

Translate this page into:
Multi-objective deep learning framework for COVID-19 dataset problems
⁎Corresponding authors. roa.mohammedqasem@ogr.altinbas.edu.tr (Roa'a Mohammedqasem), rouaaalir@gmail.com (Roa'a Mohammedqasem), maansari@iau.edu.sa (Mohammad Azam Ansari)
-
Received: ,
Accepted: ,
This article was originally published by Elsevier and was migrated to Scientific Scholar after the change of Publisher.
Peer review under responsibility of King Saud University.
Abstract
Background
It has been reported that a deadly virus known as COVID-19 has arisen in China and has spread rapidly throughout the country. The globe was shattered, and a large number of people on the planet died. It quickly became an epidemic due to the absence of apparent symptoms and causes for patients, confusion appears due to the lack of sufficient laboratory results, and its intelligent algorithms were used to make decisions on clinical outcomes.
Methods
This study developed a new framework for medical datasets with high missing values based on deep-learning optimization models. The robustness of our model is achieved by combining: Data Missing Care (DMC) Framework to overcome the problem of high missing data in medical datasets, and Grid-Search optimization used to develop an improved deep predictive training model for patients with COVID-19 by setting multiple hyperparameters and tuning assessments on three deep learning algorithms: ANN (Artificial Neural Network), CNN (Convolutional Neural Network), and Recurrent Neural Networks (RNN).
Results
The experiment results conducted on three medical datasets showed the effectiveness of our hybrid approach and an improvement in accuracy and efficiency since all the evaluation metrics were close to ideal for all deep learning classifiers. We got the best evaluation in terms of accuracy 98%, precession 98.5%, F1-score 98.6%, and ROC Curve (95% to 99%) for the COVID-19 dataset provided by GitHub. The second dataset is also Covid-19 provided by Albert Einstein Hospital with high missing data after applying our approach the accuracy reached more than 91%. Third dataset for Cervical Cancer provided by Kaggle all the evaluation metrics reached more than 95%.
Conclusions
The proposed formula for processing this type of data can replace the traditional formats in optimization while providing high accuracy and less time to classify patients. Whereas, the experimental results of our approach, supported by comprehensive statistical analysis, can improve the overall evaluation performance of the problem of classifying medical data sets with high missing values. Therefore, this approach can be used in many areas such as energy management, environment, and medicine.
Keywords
COVID-19
Hyperparameter optimization
Missing value
Deep learning
Artificial intelligence

1 Introduction
After the first cases of COVID-19 were found in China in December 2019, the epidemic expanded internationally. Since its, more than 540 million instances have been reported. Moreover, in certain situations, more serious symptoms and signs may include lung damage, severe acute respiratory syndrome (SARS), breathing trouble, and gastrointestinal problems, all of which can result in death (Andrade et al., 2022). Thousands of people are at risk from COVID-19 variants like Delta and Omicron, especially those with weakened immune systems. Artificial Intelligence (AI) is used in medical fields in previous diseases and has proven its efficiency in providing rapid medical assistance to make decisions as well as assisting in its use in medical devices to develop a treatment for diseases such as heart, diabetes, and cancer (Mohammedqasim et al., 2022), that is why scientists and researchers started using it to help them discover a cure for this dangerous epidemic. AI includes machine learning (ML), which uses these models to create brand-new data and forecast its outcomes. Whereas, symptom association activities, epidemiological recommendations for treatment, and status alert systems can use machine learning (ML) and deep learning (DL) methods to enhance the accurate assessment of medical diagnoses (Heidari et al., 2022b). Machines' ability to perform complicated tasks and make evaluations on their own might help these experts be more efficient in examining cases and applying therapies in the early stages of symptoms. In symptom identification activities, epidemiological advice, and case alert treatment, AI resources can be used to maximize analysis, treatment, and any infection-related implications (Andrade et al., 2022). AI technologies have improved COVID-19’s medical examinations, diagnosis, and predictions. These enhancements have led to better magnitude, fast replies, and more precise and effective outcomes (Heidari et al., 2022a). Controlling multiple phases may be difficult in the healthcare industry since these stages are very changeable and rely on the stage that came before them in the patient's treatment. Predictive and centralized control and command system are required to handle this variance. This will allow the system to cope with complicated data, continually learn from its experiences, and improve the algorithms that are employed in clinical prediction (Matos et al., 2021).
In this study, we proposed a novel ML framework for predicting several medical datasets that contains a high percentage of missing values by developing several deep-learning models. In comparative literature (Yaseen et al., 2019; Madrigal et al., 2018) researchers used prediction accuracy results as the main objective for classifying the diseases. The proposed approach, on the other hand, enhances the model of deep learning in phases, both regarding accuracy and complication. The two COVID-19 datasets and the cervical cancer dataset were pre-processed in the first phase due to significant levels of missing values in several features. The developed deep learning models were then improved to identify the number of layers, the number of neurons within each layer, and the kind of activation function for every layer. Finally, the output of the models with the optimal structure and learning rate was evaluated in the third stage utilizing different optimization strategies based on ideal epochs, learning rates, and (III) batch sizes.
The main study objectives can be summarized below:
• Handling high degrees of missing values in medical datasets by using the Missing Care Data Framework.
• Develop three DL models based on the hyperparameters tuning optimization to classify patients in several medical datasets.
• We performed multiple hyperparameters based on the stochastic gradient descent optimizer to select multiple combinations of optimal parameters, which greatly improved the robustness and generalizability of the model.
• The experimental results were achieved in 3 different datasets. The proposed method has been proven effective by selecting optimal hyperparameters with high evaluation performance for the prediction of many medical datasets.
This paper is structured as follows: Section 2 addresses the literature on addressing the realities of healthcare and travel, as well as the use of ML algorithms near typical healthcare equipment to identify patients with COVID-19. Section 3 presents the methods for the machine learning system used in this research. Section 4 describes the Hyperparameters and results for three medical datasets. Finally, in Section 5, the conclusion and future work are presented.
2 Related work
Recently, the Coronavirus has been of great interest to scientific researchers because of the inability of health organizations to diagnose the causes of this disease due to its genetic structure, widespread, and potential risks.
The authors (Iwendi et al., 2020) proposed an AdaBoost-enhanced RF model. To forecast the severity of the condition and whether a patient would recover or pass away, researchers in this study examined data from travelers to endemic or non-infested areas afflicted with the Coronavirus. On the used data, the model has a 94% accuracy rate and an F1 score of 0.86. In Dhamodharavadhani et al. (2020), the authors developed a Statistical Neural Network Model to predict mortality in India for the Coronavirus epidemic. This model was hybridized to predict the number of deaths and future errors by adding it to the expected value. The proposed method was able to predict contemporary states of infection, and severity, also, it will aid healthcare and government. In another study (Bari et al., 2020) the objective was to apply an algorithmic strategy for the findings with the development of an artificial intelligence ability tool to predict patients with critical conditions based on their initial data. Multiple experiments on various clinical variables yielded prediction scores ranging from 70% to 80% for predicting risky situations of patients. The COVID-19 Population Health dataset (Oyewola et al., 2021) was used to investigate the effects of noise filtering regimes using nine different ML models. Experiments were conducted using noisy and filtered data as all models showed high performance in predicting patients with COVID-19 with an accuracy of 98–100%. Three ML models were used to analyze the clinical parameters of COVID-19 patients (Oliveira et al., 2021). Reciprocal laboratory parameters and COVID-19 test results were utilized to develop two classification techniques: a first identifies COVID-19 testing for patients, while the second classifies COVID-19 test findings for health care staff. In Andrade et al. (2022) the authors proposed a qualitative methodology of machine learning (ML) algorithms collaborating on an information retrieval task to estimate clinical progression in 30,000 patients with COVID-19. To evaluate the proposed model performance four ML models were applied. Multilayer Perceptron demonstrates the best Predicting performance with an accuracy of more than 75%. In another study (Chadaga et al., 2022) Blood testing and machine learning were used to diagnose COVID-19 based on clinical and analytical data. The Synthetic Minority Oversampling Technique (SMOTE) was used to solve the data imbalance issue. Shapley Additive Explanations (SHAP) were utilized to determine the weight of each feature in the dataset. Five ML applied to classify COVID-19 patients, among all the ML models, Random Forest shows the highest result with an accuracy of 91%. In Hemdan et al. (2022) authors applied a hybrid ML framework based on a sneeze audio signals dataset for detecting COVID-19 patients. Using multi-evaluation metrics, six ML models with GA were employed to identify patients. The proposed model's accuracy ranged from 91% to 97%.
3 Methodology
The strategies we used to apply machine learning techniques to resolve the COVID-19 prediction problem are described in this section. Fig. 1 displays the proposed model for the missing dataset problem. To categorize COVID-19, a better DL model was used, and the optimal hyperparameters were found using a Grid search optimization (see Fig. 2 and Fig. 3).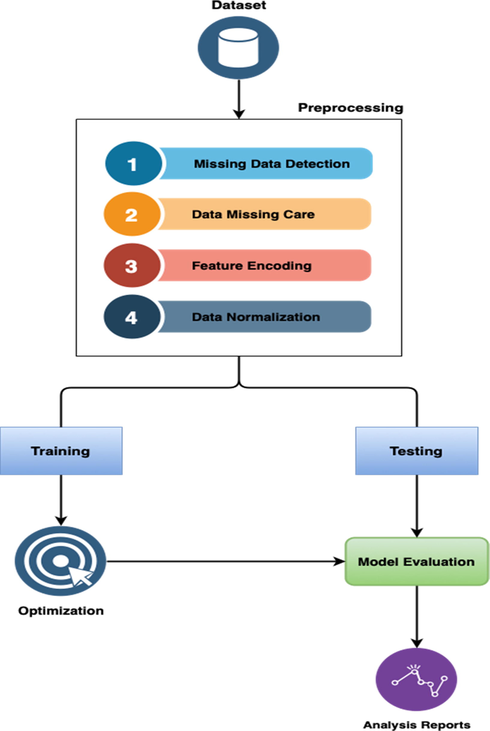
Describes the flowchart of the optimization with a machine learning system.
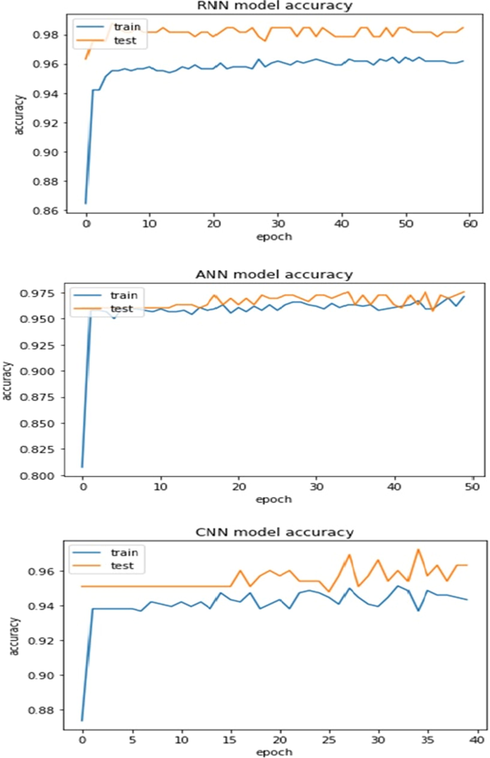
The efficiency of the deep learning method on a sampling of COVID-19 individuals and healthy persons is increasing, while loses are reducing. The convergence of the trained data line from the test (the untrained data line) also showed that the expected result is close to the truth. The convergence of the trained data line from the test (untrained data line) also showed that the expected result is close to the truth.
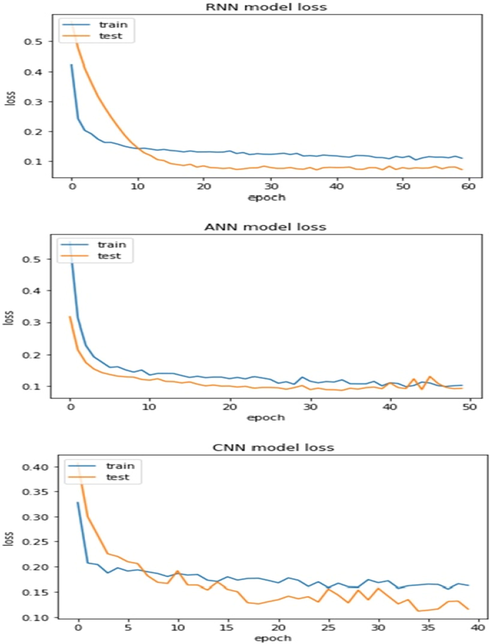
Shows the loss between training and testing sets.
3.1 Data description
In this study, we used a “Novel Coronavirus 2019 Dataset” that contains several cases of pneumonia in Wuhan, accessible from Kaggle. However, this dataset consists of (17) features and (1085) records, the relationship in the dataset between the samples of the models and the degree of their influence on the target value is extremely important.
3.2 Data pre-processing
In this work, facts preprocessing includes facts cleansing, facts normalization, and records resampling. In fact, cleansing, missing values, inconsistency, and noise (i.e., incorrect records inputs) have been eliminated.
The dataset has a huge of missing data in its features. For that, we applied the feature threshold technique to all the features that have a missing value of more than 50% (Piri, 2020). Since the machine learning works within the numeric shape so we applied the label variables categorical encoding for all records. This allocates a unique number for all records. Also, we filled the missing feature value with the mean of the feature value.
3.3 Normalization
The feature samples in our datasets have a diverse range, which causes instability in classification results. As a result, normalization is done on the sample data (Mohammedqasim et al., 2022) to keep the data in uniform distribution. Data normalization is calculated from the following equation:
wherein denotes the original feature's real value and min(F) and max(F) denote the feature's minimal and maximal values.
3.4 Caring for missing data
When reading the dataset in this study, we noticed the existence of great loss to many of the records were mostly levels of (50–98) (Jetley and Zhang, 2019), which made us take immediate and intense solutions to confront it: First of all, we will address most of the missing values, with an acceptable loss rate. Second, which has an opposite way from the first solution. It removes values with excessive levels from missing values. As a result, we will be able to obtain a dataset of acceptable completeness for adoption in the inclusion techniques.
There are a lot of processing frameworks that use statistics for inclusion strategies, while there is an insufficient degree of perfection in the facts, and therefore there are many areas that contain a large loss of information that are exceeding 50%, especially in the field of health care.
The care of missing preparation is a solution to this problem. When missing values are present, a new framework is created for it. We will use this framework to choose and keep the most important variables and get a new dataset. Caring for the new dataset starts evolved use the preliminary dataset (D), features (F), and samples (S) that contain an affordable degree of completeness, and all different information can be eliminated and keep the most effective information with an excessive degree of completeness.
3.5 Optimization system
In this paper, we evaluate and develop three DL application models (ANN, CNN, and RNN) for classifying COVID-19 infections. ANN consists of a group of specially organized neurons. Neurons and the connections between them are the main components of an artificial neural network. However, neurons have basic units of information that relate to what the ANN performance is based on. Neurons also have inter-processing components that help solve problems (Lorenzo et al., 2017). RNN provide a technique to fully model information for sequential health models, and the sequential modeling capabilities of RNNs are also suitable for many word processing packages (Agbehadji et al., 2020). CNN is used to study discriminant properties that can be applied to data sets (Gan et al., 2020), and can also extract the best sensitivity from photos and videos from big data. The extra tree is a machine learning package that is used to reduce errors, and imbalanced data, while training data for learning to get optimal results (Saeed et al., 2021).
One of the most difficult problems in developing deep learning algorithms is to find the ideal hyperparameters and to solve this problem we applied the grid search optimization model provided by the Sklearn library. The optimization model also has other advantages such as reduced predicting time, error rate, and overfitting (Hassan et al., 2018; Wang et al., 2015). Therefore, using deep learning application development together with optimization methods will reduce validation time, and losing data, and increase accuracy (Mohammedqasem et al., 2022). Given that there are numerous specified hyperparameters at each network level and charges at those other levels that would further be complicated, grid search is optimized in many phases (Decastro-García et al., 2019).
3.6 Evaluation metrics
In this study, we used multiple metrics to evaluate the performance of each developed predictive model based on different supervised deep learning algorithms (Qasim et al., 2021). The evaluation metrics use a confusion matrix to predict the correct and incorrect evaluation results by using different classification metrics: True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN).
Accuracy
The accuracy ratio scale is one of the important measures to measure the qualification of the algorithm performance for the techniques used before processing it and after processing it. The correctness and error ratio scale consists of (TP + TN). We can get the accuracy results from the following equation:
Precision
It is a scale used to measure the percentage of correct samples (TP) compared to false samples (FP). This scale is affected by the amount of imbalanced data, which is reflected in the results of the following equation:
Recall
It is a measure of the ratio of the correct expectation (TP) to its total and the ratio of the false expectation (FN). An important metric for measuring the number of correct expectations of data and the effect of imbalance of information on the results. Equation (4) is used to calculate the recall:
F1 score
It is considered one of the important metrics that are sensitive not to balance data and affect the outcome of efficiency. Equation (5) is used to calculate the F1 score:
4 Results and discussion
Each section in the information collection contains people who have Covid-19, and the data set consists of (17) features and (1085) records, the relationship in the data set between the model sample, and the degree of its effect on the target. The only reason for this study was to differentiate between Covid-19 patients and healthy people, as 0 healthy people and 1 reflect Covid-19 patients according to a standardized size scale. Validation was performed on three types of records: two Covid-19 records, and diagnostic records for cervical cancer from Wisconsin. In the beginning, we applied the missing care framework to choose the most important features that have a significant relationship with the dependent variable, the feature number decreased from (17 to 6), and also we changed all the categorical features to numeric.
In this section, after preparing the data set, we measured model quality and efficiency by dividing the data into %70 training and %30 testing. The initial study is performed using a grid search optimized on multiple values, which suggests further parameters that finally provide the best results. The following hyperparameters were employed in the analysis: (1) the Number of Layers (2) the number of neurons (3) the Activation Function (4) the Number of Momentum (5) the Loss Function, (6) the Learning Rate, (7) the Batch Size, and (8) the Number of Epochs.
In a model designed for DL, validation accuracy is tested numerous times on average. In the end, the large range of DL epochs influences productivity and losses. Timely stopping is a technique for limiting the number of training cycles and avoiding learning once the modeling output with the validating data set has just been decremented.
In numerous iterations, DL models are trained using various processing functions including (I) Linear rectifier (II) Softplus (III) Sigmoid modules for the hidden layer and a varied number of neurons. Experience has shown that different activation functions using ReLU work well. Neurons having ReLU activation functions may be spontaneously improved, have superior generalize, convergence quicker, and enable rapid computation. These findings suggest that improving neurons and hidden layers, in addition to enhancing the activation function, has a considerable impact on the effectiveness of DL models. This implies that perhaps the layer weights were appropriately specified and that multiple learning rates are employed to maintain the DL models' durability. With learning rates of 0.1, 0.01, and 0.4, it has been demonstrated that a deep learning model could properly teach healthy patients and COVID-19 patients. An initial assessment was done using a batch size range of 10–100 to explore the influence of batch size on the efficacy of the DL model, and we also noticed that the method conforms with increasing Batch-Size. To illustrate the effectiveness of deep learning models, it is necessary to introduce models of different sizes. Table 1 shows the deep learning parameters used in this work.
Parameter
RNN
ANN
CNN
Number of Layers
3
3
3
Number of Neurons
128,64,32
32,16,8
128,64,32
Activation Function
Relu
Relu
Relu
Learning Rate
0.01
0.1
0.4
Momentum
0.4
0.0
0.3
Batch Size
30
45
30
Epochs
60
50
40
Since most medical datasets can be imbalanced, so F1 score will be the main metric for comparison. Because it provides the correct prediction of the accuracy and validity of the results by using the balance between Precision and Recall. In Table 2, the best model performance was obtained in the RNN model with 98% for both accuracy and F1 score, and this algorithm is known for its ability to learn and train, which leads to strong performance. ANN and extra tree were noted as the second-best model where the F1 reached 97%. Also, CNN is the third best.
Classifier
Accuracy
Precision
F1-Score
Recall
RNN
0.98
0.98
0.98
0.98
ANN
0.96
0.97
0.97
0.97
CNN
0.95
0.95
0.95
0.95
extra tree
0.94
0.98
0.97
0.95
Table 3 shows a comparison between this study and the latest recent studies, when we compare its results with the work, we notice the effectiveness and validity of the solutions used in the system, which we obtained through a series of experiments. Recent studies used ML models with an unbalanced dataset, and the result showed that the F1 score reached 85%.
Classifier
Accuracy
F1-Score
Recall
SVM (Bari et al., 2020)
80%
–
–
Boosted Random Forest (Iwendi et al., 2020)
94%
85%
75%
ML (Chadaga et al., 2022)
91%
85%
–
Proposed
98%
98%
98%
Covid-19 from Albert Einstein Hospital
In our study, we consider this dataset to be a second dataset. The dataset comprises of multiple diagnostic research findings from the Albert Einstein Hospital in Brazil. The collection included 111 test results from 5,644 individual patients with no gender information. Missing Care framework has been implemented to remove high missing data, and the number of features has been reduced to 21 features.
Cervical cancer dataset
The cervical cancer dataset is considered a third dataset in our paper. The data set consists of 858 cases and 32 features. Dataset can be reached from Kaggle. Moreover, We discovered several incomplete data in this data set, which we deleted using the missing care framework, reducing the number of features to 17.
We used ANN, CNN, and RNN models for classification problems, then develop and improve them to use a Grid search optimization technique. Optimized DL models for high-dimensional datasets were reasonably quick, and we also examined Accuracy and losses in the second and third medical datasets, as shown in Figs. 4, 5, 6, and 7, to see whether there was any more variation in convergence outcomes. As you can see, in the second data set, our system reached maximum efficiency with an overall accuracy of 91.55% and 91.35% precision from Covid-19 patients provided by Albert Einstein Hospital. Our proposed approach offers better predictive efficiency compared to previous studies. For our third dataset on cervical cancer, all results from the F1-score evaluation, accuracy, and recall were noted above 90.00%. The best accuracy was obtained using ANN of 95% in this research.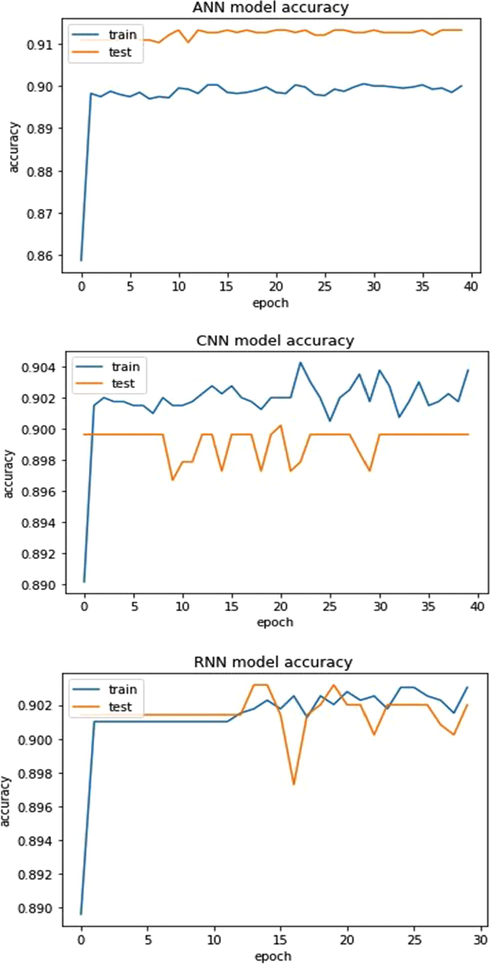
Accuracy of training and testing samples for the Albert Einstein Hospital Covid-19 dataset.
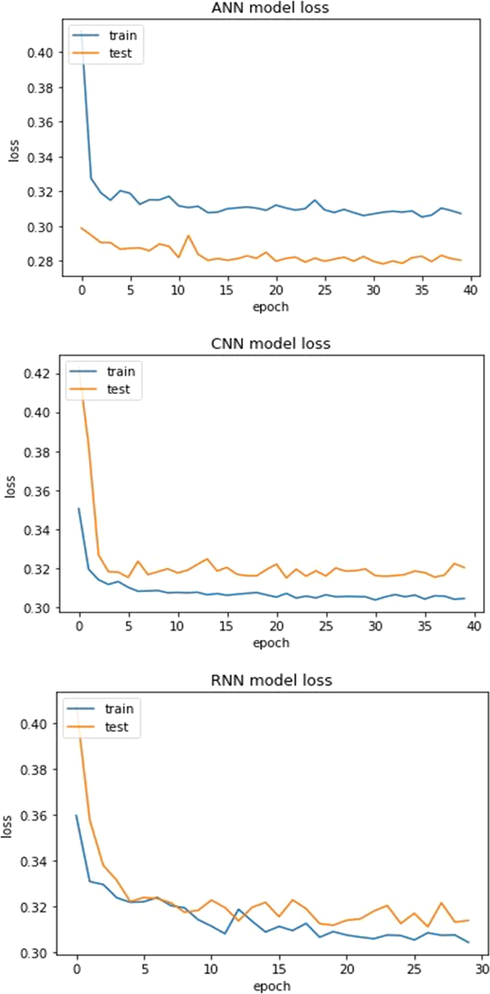
Loss value of training and testing samples during the training process for the Albert Einstein Hospital Covid-19 dataset.
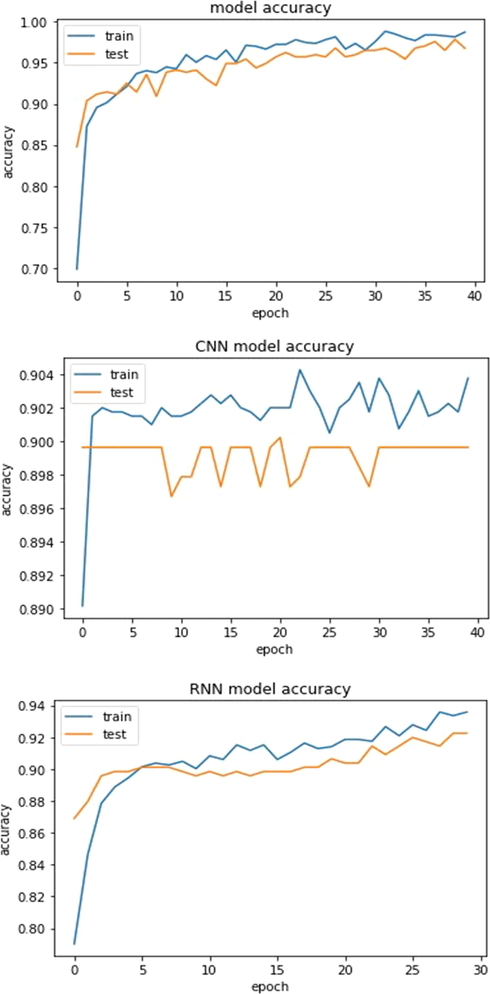
Accuracy of training and testing samples for Cervical Cancer dataset.
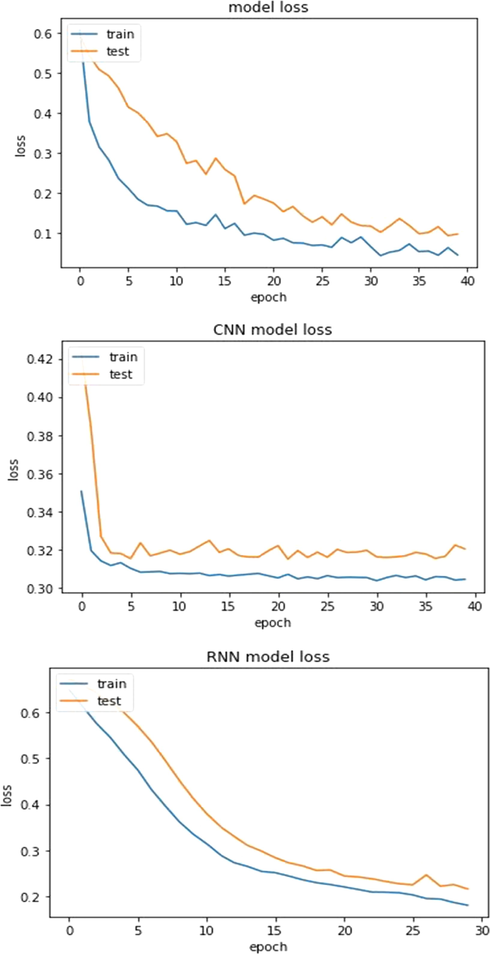
Loss value of the training and test samples during the training process for Cervical Cancer dataset.
5 Conclusions and future work
This paper proposes to develop a missing data framework that is used to solve the missing high-value issue in the COVID-19 dataset based on developed DL models. To evaluate the performance of the proposed models, we carried out the training test split with hyperparameter tuning of the DL models to increase the Network training pace, reduce the time and enhance the classification metrics for predicting the proportion of death and recovery from the Coronavirus patients, the best prediction performance of the proposed models was RNN optimization with learning rate 0.01, the ReLU activation function, Stochastic Gradient Descent (SGD) as an optimizer, and 4 layers, since both the accuracy and F1 reached 98%. While we got a 97% F1 score for both ANN and extra tree, also we reached 95% F1 with CNN. In the future, the plan is to develop a proposed study and apply it to financial companies, electric power networks, oil pipelines, product lines, and traffic systems as it contains missing values, and imbalanced signals.
Funding and Acknowledgements
The author would like to acknowledge the Deanship of Scientific Research, Imam Abdulrahman Bin Faisal University, Dammam, Saudi Arabia, for providing Grant through project number Covid19-2020-002-IRMC.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Review of big data analytics, artificial intelligence and nature-inspired computing models towards accurate detection of COVID-19 pandemic cases and contact tracing. Int. J. Environ. Res. Public Health. 2020;17(15):1-16.
- [CrossRef] [Google Scholar]
- Andrade, E.C.D., Pinheiro, P.R., Barros, A.L.B.D.P., Nunes, L.C., Pinheiro, L.I.C.C., Pinheiro, P.G.C.D., Filho, R.H., (2022a). Towards Machine Learning Algorithms in Predicting the Clinical Evolution of Patients Diagnosed with COVID-19. Applied Sciences 2022, Vol. 12, Page 8939, 12(18), 8939. https://doi.org/10.3390/APP12188939
- Towards an Artificial Intelligence Framework for Data-Driven Prediction of Coronavirus Clinical Severity. CMC. CMC. 2020;63(1):537-551.
- [CrossRef] [Google Scholar]
- Clinical and Laboratory Approach to Diagnose COVID-19 Using Machine Learning. Interdiscipl. Sci. – Comput. Life Sci.. 2022;14(2):452-470.
- [CrossRef] [Google Scholar]
- Effect of the Sampling of a Dataset in the Hyperparameter Optimization Phase over the Efficiency of a Machine Learning Algorithm. Complexity. 2019;2019
- [CrossRef] [Google Scholar]
- COVID-19 Mortality Rate Prediction for India Using Statistical Neural Network Models. Front. Public Health. 2020;8(August):1-12.
- [CrossRef] [Google Scholar]
- Integrating TANBN with cost sensitive classification algorithm for imbalanced data in medical diagnosis. Comput. Ind. Eng.. 2020;140(December 2019):106266
- [CrossRef] [Google Scholar]
- Hassan, M.ul, Sabar, N.R., Song, A., 2018. Optimising Deep Learning by Hyper-heuristic Approach for Classifying Good Quality Images. Lect. Notes Comput. Sci. (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 10861 LNCS, 528–539. https://doi.org/10.1007/978-3-319-93701-4_41.
- The COVID-19 epidemic analysis and diagnosis using deep learning: A systematic literature review and future directions. Comput. Biol. Med.. 2022;141:105141
- [CrossRef] [Google Scholar]
- A privacy-aware method for COVID-19 detection in chest CT images using lightweight deep conventional neural network and blockchain. Comput. Biol. Med.. 2022;145:105461
- [CrossRef] [Google Scholar]
- CR19: a framework for preliminary detection of COVID-19 in cough audio signals using machine learning algorithms for automated medical diagnosis applications. J. Ambient Intell. Hum. Comput.. 2022;1–13
- [CrossRef] [Google Scholar]
- COVID-19 patient health prediction using boosted random forest algorithm. Front. Public Health. 2020;8(July):1-9.
- [CrossRef] [Google Scholar]
- Electronic health records in IS research: Quality issues, essential thresholds and remedial actions. Decis. Support Syst.. 2019;126:113137
- [CrossRef] [Google Scholar]
- Lorenzo, P.R., Nalepa, J., Ramos, L.S., Pastor, J.R., 2017. Hyper-parameter selection in deep neural networks using parallel particle swarm optimization. GECCO 2017 - Proceedings of the Genetic and Evolutionary Computation Conference Companion, 1864–1871. https://doi.org/10.1145/3067695.3084211.
- Madrigal, F., Maurice, C., Lerasle, F., 2018. Hyper-parameter optimization tools comparison for multiple object tracking applications. Mach. Vision Appl. 30(2), 269–289. https://doi.org/10.1007/S00138-018-0984-1.
- COVID-19, stock market and sectoral contagion in US: a time-frequency analysis. Res. Int. Bus. Financ.. 2021;57:101400
- [CrossRef] [Google Scholar]
- Real-time data of COVID-19 detection with IoT sensor tracking using artificial neural network. Comput. Electr. Eng.. 2022;100:107971
- [CrossRef] [Google Scholar]
- Mohammedqasim, H., Mohammedqasem, R., Ata, O., Alyasin, E.I., 2022. Diagnosing Coronary Artery Disease on the Basis of Hard Ensemble Voting Optimization. Medicina 58(12), 1745. https://doi.org/10.3390/MEDICINA58121745.
- Oliveira, R.F.A.P., Bastos-Filho, C.J.A., Medeiros, A.C.A.M.V.F., Buarque, P., Freire, D.L., 2021. Machine Learning Applied in SARS-CoV-2 COVID 19 Screening using Clinical Analysis Parameters. IEEE Lat. Am. Trans. 19 (6), 978–985. https://doi.org/10.1109/TLA.2021.9451243.
- Oyewola, D.O., Dada, E.G., Misra, S., Damaševičius, R., 2021. Predicting COVID-19 Cases in South Korea with All K-Edited Nearest Neighbors Noise Filter and Machine Learning Techniques. Information 12(12), 528. https://doi.org/10.3390/INFO12120528.
- Missing care: A framework to address the issue of frequent missing values;The case of a clinical decision support system for Parkinson’s disease. Decis. Support Syst.. 2020;136
- [CrossRef] [Google Scholar]
- Qasim, H.M., Ata, O., Azam Ansari, M., Alomary, M.N., Alghamdi, S., Almehmadi, M., Artusi, A., Guerra, A., Schirinzi, T., 2021. Hybrid Feature Selection Framework for the Parkinson Imbalanced Dataset Prediction Problem. Medicina 57(11), 1217. https://doi.org/10.3390/MEDICINA57111217.
- Fault diagnosis based on extremely randomized trees in wireless sensor networks. Reliab. Eng. Syst. Saf.. 2021;205
- [CrossRef] [Google Scholar]
- Wang, L., Feng, M., Zhou, B., Xiang, B., Mahadevan, S., 2015. Efficient Hyper-parameter Optimization for NLP Applications. 17–21.
- Deep learning hyper-parameter optimization for video analytics in clouds. IEEE Trans. Syst., Man, Cybern.: Syst.. 2019;49(1):253-264.
- [CrossRef] [Google Scholar]




