

Translate this page into:
A semi-parametric estimator of the quantile residual life for heavily censored data
⁎Corresponding author, Second address: Department of Mathematics and Computer Science, Faculty of Science, Suez University, Suez, Egypt. drkayid@ksu.edu.sa (M. Kayid),
-
Received: ,
Accepted: ,
This article was originally published by Elsevier and was migrated to Scientific Scholar after the change of Publisher.
Peer review under responsibility of King Saud University.
Abstract
The p-quantile residual life function summarizes the lifetime data in a useful and simple concept and in units of time. For uncensored data or when the upper tail of the observations is not censored, this function can be estimated by applying the well-known Kaplan-Meier survival estimator. But, when research terminates in heavy right-censored lifetime data which is the case of many biomedical and survival studies, the p-quantile residual life function is not estimable in this way. In this paper, we propose a novel semi-parametric estimator of the p-quantile residual life function in such cases. It combines the nonparametric Kaplan-Meier survival estimator with an approximated tail model motivated by the extreme value theory. The proposed estimator has been examined by a simulation study and applied to a lifetime data set in the sequel.
Keywords
62N86
Right censorship
Kaplan-Meier estimator
Generalized Pareto model
Extreme value theory

1 Introduction
In many fields such as epidemiology, biology, medicine, and survival analysis, the researcher's interest is on time to event data, e.g., the survival time of a creature or time of tumor recurrence. The most familiar measure for induction and analyzing such data is the survival function, which for every time t ≥ 0 computes the probability of the event to occur beyond time t. The p-quantile residual life (p-QRL) function, 0 < p < 1, is another relevant measure in this context providing an intuitive meaning. For example, in the case p = 0.5, we have a median residual life which at time t captures the remaining time that half of the survived population at t will experience the event. This fact that unlike the survival function, the p-QRL is expressed in the time units by which the observations are measured makes its interpretation easier.
Besides, in reliability analysis, the p-QRL measure is quite useful for describing the lifetime of manufactured devices. For instance, it is very likely for some devices to fail in the early stages of their work. It is the case especially when the failure rate has a bathtub shape. Then we can consider a burn-in time t₀ that every produced device should pass before releasing to field operation. We can find such t₀ that maximizes the p-QRL function. For more details, we refer to Conboy et al. (2020).
Sometimes, time events may be invisible due to some censoring mechanism which cannot be naturally avoided. During the study, some items may be lost to follow-up before experiencing the event or reaching the end-time of the study. They are said to be right-censored. However, items passing the end-time of the study are referred to be Type I censored.
Given a right-censored data set, the survival function can be estimated using Kaplan-Meier (KM) estimator proposed by Kaplan and Meier (1958). The KM survival plot, which summarizes the possibly censored data graphically, has been vastly used in the aforementioned areas. On the other hand, taking account of right censoring, many authors focused on the problem of estimating the p-QRL function. Among them, we refer to Jeong et al. (2008), Franco-Pereira and de Uña-Álvarez (2013), Jeong and Fine (2013), Lin et al. (2015), Zhang et al. (2015), and Lin et al. (2016).
One drawback in right-censored data corresponds to the case that the upper tail and especially last observations are censored. In this case, the KM survival estimator does not vanish to zero in the support tail. Thus, the inverse of the survival function at small values will not be estimable by the KM estimator. Therefore, we cannot estimate the p-QRL function especially at large values (cf. Franco-Pereira and de Uña-Álvarez (2013)). The results of many types of research consist of highly censored data sets in which major of their large observations are censored. For such data sets, we may not estimate the p-QRL function, namely, qp(t), (for example, the median residual life) even at rather small ts. Therefore, our idea is to provide an approach to estimate the p-QRL function for all t values.
In this paper, we propose a new semi-parametric method for estimating the p-QRL function that overcomes the problem of dealing with high censored lifetimes. It applies the KM estimator of the survival function in a proper threshold time u, and the generalized Pareto distribution (GPD) as an approximated tail model (Coles (2001)). The approximation of the tail model is motivated by the results of the extreme value theory, refer to Castillo et al. (2005) and Coles (2001). Then, the uncensored observations in the tail (which we suppose to be greater than the threshold u) are used to provide the maximum likelihood estimation of the model parameters.
The paper has been organized as follows. Section 2 provides preliminaries and states the problem. In Section 3, the new estimator of the p-QRL function has been proposed. The attributes of this estimator are investigated through a simulation study in Section 4. In Section 5, the results of a research investigation of the effect of some treatments on the colon recurrence time are considered. Then the first quartile residual life (0.25-QRL) and the median residual life functions are estimated. Finally, a conclusion is drawn in Section 6.
2 Preliminaries: Non-parametric estimation of -QRL
Let the random variable which represents the lifetime of an object follows the survival function . The -QRL function is defined as
When the last observation has not been censored, the estimator is well-defined for all . Otherwise, it is not defined for all values where stands for . When , that is falls below the computable range of the inverse of KM survival function. Fig. 1 explains the issue graphically.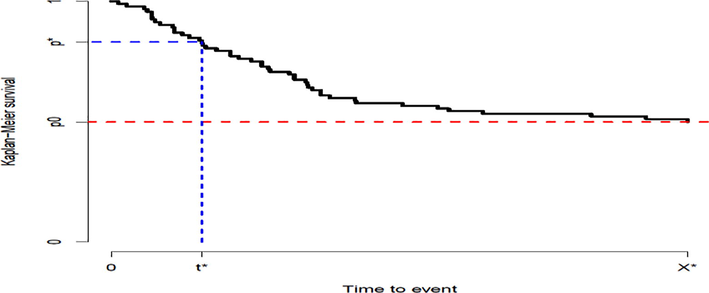
This illustrative plot shows that when large observations have been censored the QRL function () is not estimable for by the inverse of the KM survival function. Here, and equal to () and () respectively.
3 Semi-parametric estimation of -QRL
This section aims to propose a semi-parametric estimator of for . Note that if , then
Consider an arbitrary sequence of i.i.d. random variables T1,T2,… following the same distribution of T and let be maximum of the first elements of this sequence. Let there exist sequences and of constants such that the normalized random sequence converges weakly to non-degenerate distribution . Then, accommodates GEV
On the other hand, the max-stability property of the GEV model states that equals with . Thus, for , belongs to this family too, notationally, , . In the light of the preceding discussion, we can approximate for some threshold by:
Since is sufficiently large, we have
Then, by simplifying the right side of this approximation, it follows that
: light tail with finite upper bound .
: exponential tail.
: heavy tail.
When , the th moment of GPD is infinite. So, when we are confident of finite mean and/or variance it may be useful to restrict the parameter space by . However, such restriction is not recommended in a neat semi-parametric framework. For GDP, the inverse of the survival function equals with
To implement the method for censored data, let , and be true survival time, random right censoring time, and a constant time presenting end of the study, respectively. Taking , we observe and . To estimate for , we suggest the following steps.
At first we should select a proper value for which is a trade-off between the accuracy of the tail model approximation and the share of the observations available for estimating the model parameters. Large values of improve the approximation of the model but limit the volume of the observations for estimation of the parameters. Yet, there is not any standard approach for finding an optimum value for . Nevertheless, it seems that the percent quantile of the observed (uncensored) times be a proper value for threshold . That is percent of observed and uncensored events lie between and (see Alvarez-Iglesias et al. (2015) for a similar discussion).
Construct new sample for all censored or uncensored observations grater than and let denote the count of them. Applying this data set, we obtain the maximum likelihood estimation of the parameters of GPD model . The likelihood function is
Now, in the light of Relations and , we propose the estimator
Variance (bias) of this estimator is comprised of variation (bias) due , and along with their covariance and seems to be more complicated than to be expressed by a closed expression. In the case of the heavy tail of the true lifetime model which causes that , it’s variance increases with . Fortunately, we can use the bootstrap method to estimate its bias and variance and in turn approximate confidence intervals. However, simulation studies heuristically imply that bias and variance reduce strongly by sample size.
4 Simulation study
To design a simulation framework, we consider gamma, log-normal, and Weibull models along with four censoring schemas. Both right censoring and Type I censoring have been taken in account. Once the model and the censoring scheme determined, replicates of samples of sizes and have been drawn and censored. Then for two values (corresponding to the median residual life function) and the proposed estimator has been computed by each of replicates. For each replicates the bias is computed by the difference . We report their mean and standard deviation as bias and sd in Tables 1–3. In addition, that shows the mean of the estimation values has been entered in the tables.
n
p
(0.1,0.3)
(0.2, 0.2)
(0.2, 0.1)
(0.1, 0.05)
500
2.5821
3.7561
2.6533
2.3134
0.75
bias
0.5342
1.7089
0.6085
0.2380
sd
1.9196
4.2724
2.4804
2.6121
1.2076
1.2915
1.1338
1.1159
0.50
bias
0.1893
0.2644
0.1124
0.0619
sd
0.5883
0.9855
0.5585
0.3956
1000
2.2879
2.2565
2.3828
2.0106
0.75
bias
0.2397
0.2049
0.3381
−0.0652
sd
1.4182
1.4428
2.0186
0.7124
1.0744
1.1491
1.0932
0.9911
0.50
bias
0.0562
0.0222
0.0718
−0.0337
sd
0.3949
0.4405
0.3540
0.2237
n
p
(0.1, 0.3)
(0.2, 0.2)
(0.2, 0.1)
(0.1, 0.05)
500
0.5533
0.5014
0.4852
0.4907
0.75
bias
0.1305
0.0832
0.0631
0.0586
sd
0.3290
0.3003
0.2453
0.2078
0.2460
0.2494
0.2369
0.2276
0.50
bias
0.0364
0.0426
0.0276
0.0126
sd
0.1427
0.1129
0.0778
0.0809
1000
0.5003
0.4807
0.4664
0.4528
0.75
bias
0.0773
0.0624
0.0438
0.0204
sd
0.2793
0.1903
0.1600
0.1349
0.2212
0.2128
0.2197
0.2334
0.50
bias
0.0114
0.0059
0.0103
0.0183
sd
0.0657
0.0609
0.0604
0.0608
n
p
(0.1,0.3)
(0.2,0.2)
(0.2,0.1)
(0.1,0.05)
500
5.3993
5.9644
4.5763
3.3337
0.75
bias
2.3480
2.8360
1.5028
0.4228
sd
7.5687
8.3373
5.9047
2.0737
1.8733
2.0957
1.8772
1.5307
0.50
bias
0.3073
0.4824
0.2973
0.0435
sd
1.1001
1.1999
0.9687
0.5527
1000
3.6093
3.9250
3.8343
3.1620
0.75
bias
0.5612
0.7976
0.7619
0.2489
sd
2.4968
3.4923
2.9527
1.0536
1.7904
1.9712
1.6409
1.5194
0.50
bias
0.2255
0.3588
0.0618
0.0333
sd
0.6970
0.9163
0.5111
0.3830
To provide censored random samples, some proper combinations of right censoring and Type I censoring have been selected. Let and represent the proportions of Type I censoring and random right censoring respectively. The simulation process starts withdrawing a sample of size from the true model that is the distribution of following survival function . We take the distribution of the right censoring random variable to be uniform on the interval . Moreover, according to type I censoring, the observations will be censored if they are greater than . For fixed values and , we should compute and through the equations and . It is straightforward to show that these equations can be simplified to the system equationswhich can be solved in terms of and by standard numerical methods. Then, we can pursue the procedure according to the bellow steps.
Generate a random sample from the true model with the survival function .
Generate a random sample of uniform as random censoring times.
Compute the observable data and for .
Repeat steps 1 to 3 times.
Let be the maximum observed (uncensored) lifetime of the sample in the th replication, . Then, take to be the mean of . Of course, is suitable for applying in the simulation, since it is expected that will not be computed by the KM estimator .
For each replication, compute introduced by .
Results of simulations have been gathered in Tables 1–3. All tables agree on the fact that the bias and sd values show a strong reduction from to .
5 Applications
Moertel et al (1995) reported a data set related to one trial for investigation of the effectiveness of Fluorouracil (5-FU) and Levamisole (Lev) in reducing the recurrence rate of stage B/C colon cancer. The trial involves three treatments for Observation (Obs), Levamisole (Lev), and Levamisole plus 5-FU (Lev + 5-FU). Under right censoring, for every person, both events of recurrence of cancer and death have been recorded. We focus on the recurrence times which near percent of them have been censored. For each of the three treatments and the overall data, the KM survival function has been drawn in Fig. 2, which reveals high censoring rates.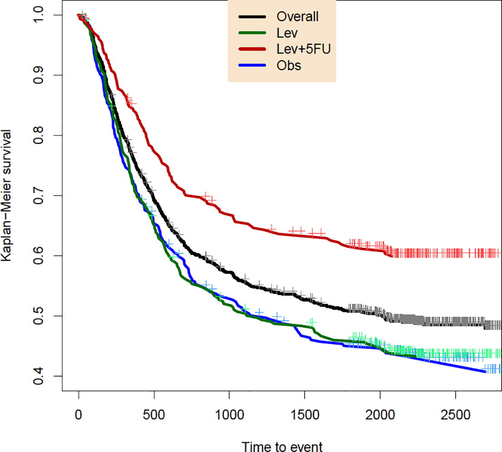
The KM survival plot for three treatments and the overall data. Every censored item is included by a+.
We are interested in the estimation of the first QRL function and the median residual life function respectively corresponding to and . As before, let stand for the minimum of values where the QRL can not be computed directly by inverting the KM survival function. Values of computed for these data sets have been gathered in Table 4.
Obs
Lev
Lev + 5-FU
Overall
p
0.25
0.5871
230668
191449
0636
99
The first quartile residual life function and the median residual life function have been plotted in Figs. 3 and 4 respectively. For these functions have been estimated by and have been plotted by a thinner line.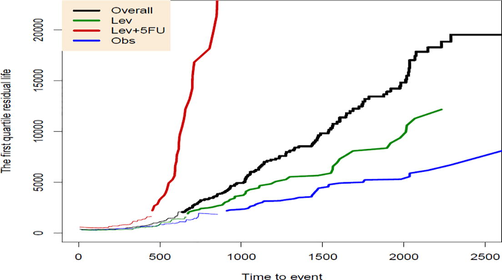
The first quartile residual life function for three treatments and the overall data.
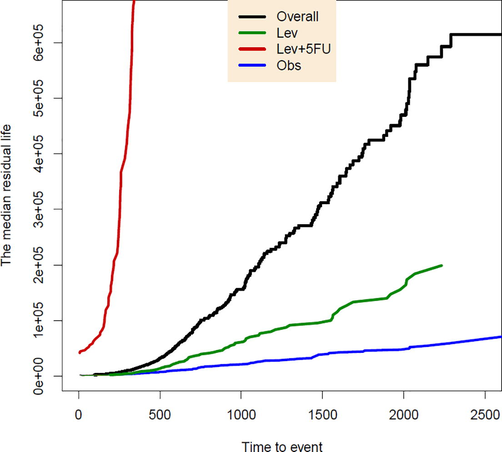
The median residual life function for three treatments and the overall data.
These figures distinguish larger median residual life and first quartile residual life functions for Lev + 5-FU treatment, which are even noticeably above the QRL functions related to overall data. However, for two treatments Obs and Lev, both of these QRL functions are comparable and lie below the QRL functions of the overall group.
6 Conclusion
The p-quantile residual life function summarizes the lifetime data in a useful and simple concept and in units of time. For uncensored data or when the upper tails of the observations are not censored, this function can be estimated by applying the well-known Kaplan-Meier survival estimator. However, when research terminates in heavy right-censored lifetime data, which is the case of many biomedical and survival studies, the p-quantile residual life function is not estimable in this way. In the current investigation, we proposed a novel semi-parametric estimator of the p-quantile residual life function in such cases. The proposed estimator has been examined by a simulation study and applied to a real lifetime data set in the sequel.
Funding
This Project was funded by the National Plan for Science, Technology, and Innovation (MAARIFAH), King Abdulaziz City for Science and Technology, Kingdom of Saudi Arabia, Award Number (14-MAT2052-02).
Acknowledgments
The authors are grateful to anonymous three referees for their constructive comments that lead to an improvement in the quality of the paper. The authors would like to extend their sincere appreciation to the strategic technology program of the National Plan for Science, Technology and Innovation in the Kingdom of Saudi Arabia for its funding this project No. 14-MAT2052-02.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Summarising censored survival data using the mean residual life function. Stat. Med.. 2015;34:1965-1976.
- [Google Scholar]
- Extreme Value and Related Models with Applications in Engineering and Science. Hoboken, New Jersey: Wiley Series in Probability and Statistics Wiley; 2005.
- An Introduction to Statistical Modeling of Extreme Values. London: Springer; 2001.
- Using business analytics to enhance dynamic capabilities in operations research: a case analysis and research agenda. Eur. J. Operation. Res. Elsevier. 2020;281(3):656-672.
- [Google Scholar]
- Counting Processes and Survival Analysis. New York: Wiley; 1991.
- Estimation of a monotone percentile residual life function under random censorship. Biom. J.. 2013;55:52-67.
- [Google Scholar]
- Nonparametric inference on cause-specific quantile residual life. Biom. J.. 2013;55:68-81.
- [Google Scholar]
- Nonparametric inference on median residual life function. Biometrics. 2008;64:157-163.
- [Google Scholar]
- Nonparametric estimation from incomplete observations. J. Am. Stat. Assoc.. 1958;53:457-481.
- [Google Scholar]
- Inference on quantile residual life function under right-censored data. J. Nonparametr. Stat.. 2016;28:617-643.
- [Google Scholar]
- Conditional quantile residual lifetime models for right-censored data. Lifetime Data Anal.. 2015;21:75-96.
- [Google Scholar]
- Fluorouracil plus Levamisole as an effective adjuvant therapy after resection of stage II colon carcinoma: a final report. Ann. Intern. Med.. 1995;122:321-326.
- [Google Scholar]
- Smoothed estimator of quantile residual lifetime for right-censored data. J. Syst. Sci. Complex. 2015;28:1374-1388.
- [Google Scholar]




