

Translate this page into:
A new flexible extension of the Lindley distribution with applications
⁎Corresponding author. drkayid@ksu.edu.sa (Mohamed Kayid)
-
Received: ,
Accepted: ,
This article was originally published by Elsevier and was migrated to Scientific Scholar after the change of Publisher.
Abstract
A new general family of distributions based on the Lindley model was introduced. Some properties of the proposed model, including moments, quantiles, and order statistics are presented. In addition, some reliability measures of this model were investigated. The parameters were estimated using the moments and the maximum likelihood methods for complete and right-censored data. Then, the behavior of the maximum likelihood estimator was investigated in a simulation study. Finally, the model was applied to the analysis of two data sets to demonstrate its usefulness.
Keywords
62N01
62N05
Mixture models
Gamma distribution
Failure rate
Mean residual life
Mean inactivity time

1 Introduction
In recent years, there have been many papers dealing with the Lindley distribution and its applications; see Lindley (1958), Ghitany et al. (2008), Bakouch et al. (2012), Al-Mutairi et al. (2013) and Cakmakyapan and Kadilar (2017). Many authors have introduced some generalizations and/or extensions to the Lindley model by increasing either the number of underlying parameters or the number of mixed density functions, see for example (Ghitany et al., 2011, Al-Babtain et al., 2014, Abouammoh et al., 2015, Cordeiro et al., 2018, Abouammohm et al., 2020). The main objective of these works is to introduce more flexible probability distributions to model different types of lifetime variables in real applications. The Lindley model is defined by its probability density function (PDF) as which is a mixture of the gamma distribution with shape parameter 1 and scale parameter , and with weights and , respectively. The cumulative distribution function (CDF) of the Lindley model is:
In connection with the generalization of the Lindley distribution, Shanker (2016a,b) introduced the Aradhana distribution with the following PDF and CDF, respectively: and
This version of the Aradhana model was used to fit the lifetime data of 20 patients receiving an analgesic reported in Gross and Clark (1976) to relief times (in minutes) and a dataset representing aircraft window thickness cited in Fuller et al. (1994). In addition, Welday and Shanker (2018) have provided a generalization of this model to the two-parameter Aradhana distribution with the PDF:
Moreover, Shanker and Shukla (2018) introduced the power Aradhana model whose PDF is given by the PDF of , namely and the CDF
They used this model to analyze the tensile strength measured in GPA of 69 carbon fibers tested in tension at a length of 20 mm (Bader and Priest, 1982).
Most data sets are mixtures of multiple populations, and usually no information is available to determine the associated subpopulation of each data point. For example, the lifetime of a device may be recorded without regard to manufacturer or date of production, or some measurements of humans may be reported without regard to geographic location or blood type. When the measured characteristics depend on data that are not available (manufacturer, production date, geographic location, or blood type), the data are said to be mixed. It is not easy to find data sets that are not mixed in some way, since in almost every case some relative covariates are not observed. There are many applications and statistical frameworks in which mixture models occur. For detailed discussions, see Titterington et al. (1985), Lindsay (1995) and Ord (1972).
The above models are mixtures of two or three gamma distributions with different shape parameters. However, in many situations, the data may come from more than two or three sub-populations. For example, a device may be manufactured by more than three factories in a company, etc. Therefore, it is better to use a mixture model with an adjustable number of underlying sub-models. The aim of this paper is to investigate such a flexible model, which also generalizes the previous models.
In this paper, we present in Section 2 a new generalized model that incorporates the above and many other models. Section 3 presents the main statistical and reliability properties of this new model. Parameter estimation for complete and right-censored data is discussed in Section 4. In Section 5, a simulation study was conducted to investigate the behavior of the MLE. Finally, the proposed model and some competing models were fitted to two datasets to show their usefulness.
2 The Abouammoh-Alrasheedi model
One can include most of the previously mentioned models in a general family from which many more special cases can be derived and studied. Statistical and reliability properties, estimation of the underlying parameters, and fitting the derived model to real data will make the models available in the literature even richer with more flexible manipulations. We now give the following definition.
The random variable X is said to have Abouammoh-Alrasheedi distribution with parameters , denoted by if its PDF be of the form
One can, without difficulty, verify that this is a PDF, i.e.,
. For integer m, it can be written as a mixture of gamma distributions, so by Theorem 3 of Atienza et al. (2006), it is identifiable. More precisely
where
The constant coefficient of the PDF (2) can be written as the following form:
Since is a PDF, we have
On the other hand, by straightforward algebra we have which shows the result immediately. □
Some of special cases of the are listed in the following.
-
For and , it reduces to the exponential distribution.
-
For and it gives the Lindley distribution.
-
For and reduces to Aradhana distribution which is a mixture of and with weights and , see Shanker (2016a,b).
-
For , and becomes a generalized Aradhana distribution and is also a generalization of the Lindley distribution.
3 Statistical and reliability properties
Now, we derive the main statistical and reliability properties of the proposed distribution. The cumulative distribution function of
is
The
moments of
model is
The
moments of a distribution with the reliability function R equals to
Thus, for
we have
Now, we have
By the fact that
model can be written as a mixture of the corresponding moments of the underlying gamma distributions, we have another representation of the
moments
By straightforward algebra the moment generating function of
can be simplified as the following form.
The quantile function is of the form
The Lorenz curve provides a graphical representation of the wealth distribution and is defined to be
It can be checked easily that for it can be simplified as follows. where .
Let represents a sample of . The PDF of order statistics, , is
Thus the PDF of series and parallel systems with such identical components reduces to and respectively.
3.1 Reliability measures
The failure rate function is an important measure in reliability theory and survival analysis. Assuming that an event has not yet occurred by time x, it represents the instantaneous risk of occurrence at time x. For
, the failure rate function is:
The MRL function of distribution is of the form
We can write
The integral in the right side of (14) can be simplified as the following.
Applying ()()()(13)–(15) the result follows. □
The p-QRL function, denoted by , is the conditional pth quantile of the remaining life of an object provided that it is still alive at x, precisely where . For , by (11) we have
Figs. 1–4 show the PDF, failure rate function, MRL function, and median residual life function, respectively. The failure rate shows an increasing shape and the MRL and median residual life functions show a decreasing shape. The MRL shows larger values than the median residual lifetime, indicating that the conditional residual lifetime is skewed to the right.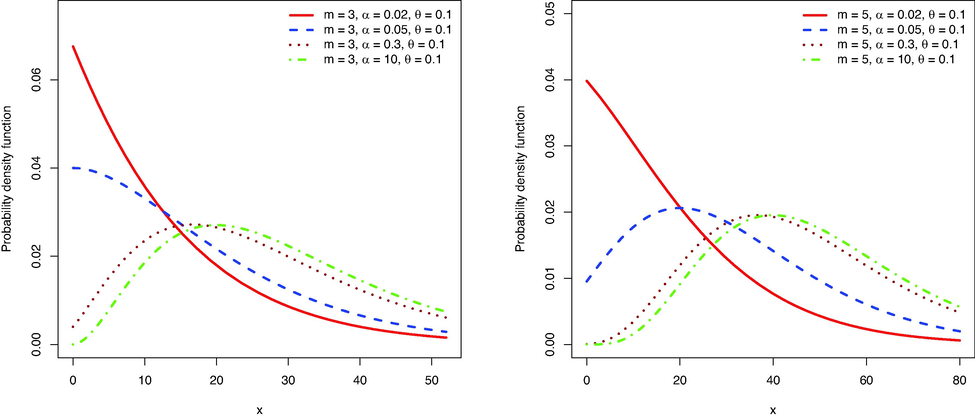
The PDF of
for some values of parameters.
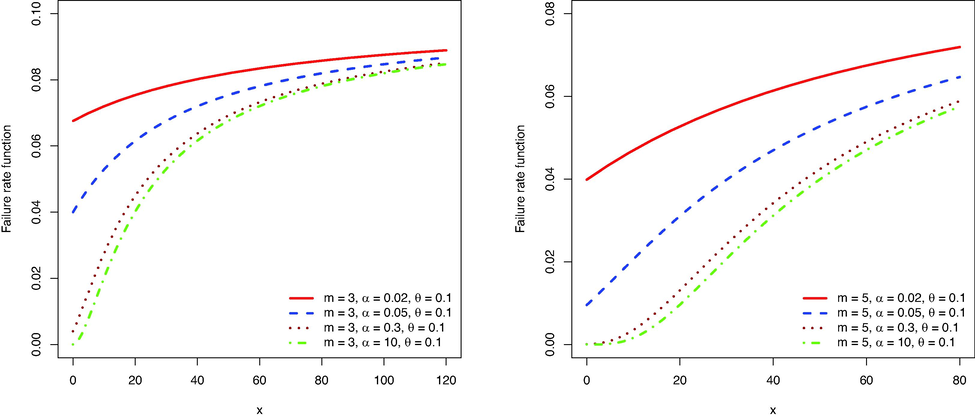
The failure rate function of
for some values of parameters.
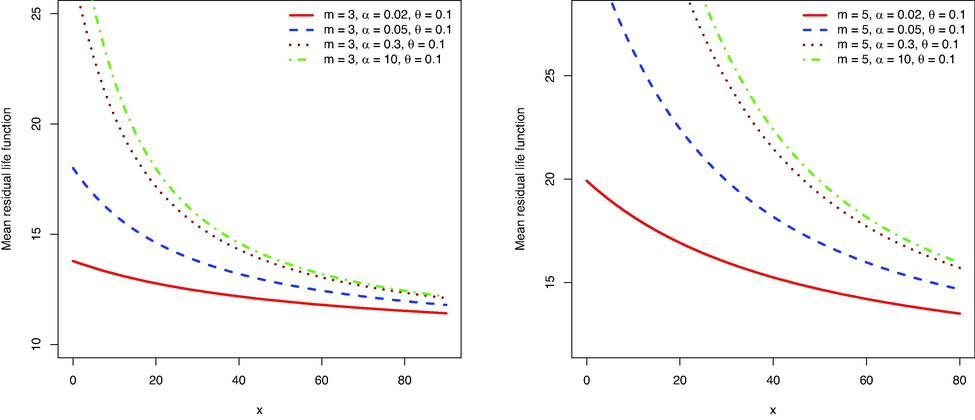
The mean residual life of
for some values of parameters.
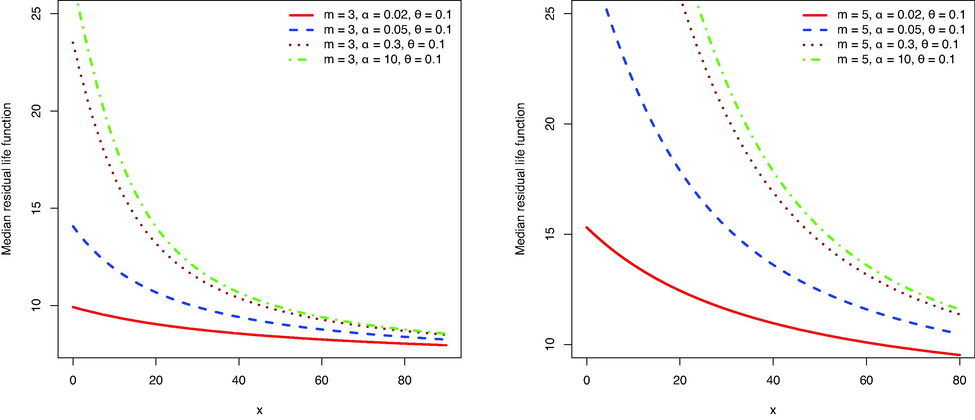
The median residual life of
for some values of parameters.
The mean inactivity time (MIT) at time , represents the mean of elapsed time at x given the event has been occurred before x, mathematically,
The MIT function of
distribution is of the form
We have
Now, we can simplify the integral in the last expression as follows.
On the other hand
Then, the results follows by (17), (18) and (19). □
The quantile inactivity time is an alternative for MIT and represents, at time x, the quantile of the elapsed time given the event occurred before x. For a distribution F, it is defined by:
Fig. 5 shows the MIT and the median inactivity time (
) of
for some parameters and shows increasing and convex forms. The greater values of the MIT indicate that the conditional distribution of the elapsed time is skewed to right.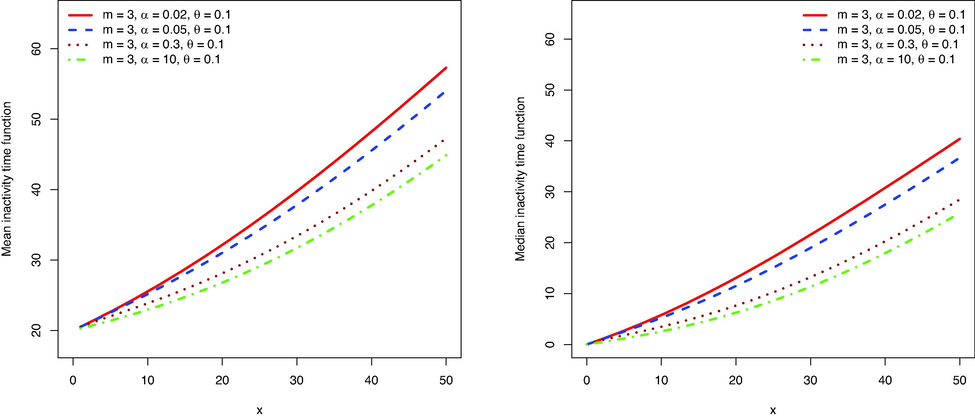
Left: The MIT of
for some values of the parameters. Right: The median inactivity time of this distribution for the selected values of the parameters.
4 Estimation of the parameters
Let m be known. By the moments method and applying (9), we can estimate by minimizing the following expression.
So, the moments estimator is
The moment estimates can be used as initial values for maximizing the log-likelihood function and finding the maximum likelihood estimator (MLE).
Let m be known and represents a realization from , the log-likelihood function is
Also, the likelihood equations are as follows: and
The MLE can be calculated by maximizing the log-likelihood function or by solving the likelihood equations. If m is not known, which is usually the case, we can estimate the parameters for a range of m values and then choose the best model based on the Kolmogorov–Smirnov (K-S) statistic or other criteria.
The Fisher information matrix for the is of the form where Let . Let stands for a sample from . Then, the MLE, , converges in distribution to bivariate normal in which is the inverse of the information matrix.
Suppose that events are subject to random right censorship. A random event is said to be right-censored if the only information about the event is that it is greater than the random censoring variable , i.e. . So, the observations of a right censored random sample consist of and , where if the event is not censored, , and if the event is censored, . Let we have one right censored sample . Then, the log-likelihood function is in which f and R are the PDF and the reliability functions of the respectively. It is easy to check that the log-likelihood function simplifies to
5 Simulation
Given that is a mixture of gamma distributions, we can extract a random sample of size n from this model as described in the following steps:
-
Simulate one random instance of multinomial distribution with parameters ,…, , where is defined by (3). Let the simulated instance be which will satisfy .
-
For every , simulate one random sample of the gamma distribution of size . Then combine these samples to provide one sample of size n from .
-
Here, the degenerate random variable with mean has been used as the random censorship variable . Given the censorship percentage p, we have where is defined in (11).
The simulation results have been abstracted in Table 1. We have considered two values
and
for censorship rate. Every cell of the table shows the results for one run. In every run, we provide
replicates of samples of size
. For every sample the MLE,
has been computed. Then the bias (B), absolute bias (AB) and the mean squared error (MSE) for both
and
have been computed. These measures are defined in the following relations for
. They are defined similarly for
.
and
n
m
B
AB
MSE
B
AB
MSE
80
3
0.02, 0.05
0.004988
0.013574
0.000373
0.006054
0.018217
0.000646
0.000600
0.008016
0.000104
-0.000659
0.011561
0.000194
0.3, 5
0.983335
1.212043
3.712165
1.175853
1.455283
5.641408
0.848339
1.278958
2.889727
0.980640
1.536448
4.373064
0.05, 2
0.461190
0.499459
0.682545
0.616871
0.658195
1.280510
0.470890
0.579849
0.623839
0.561123
0.705742
0.986987
5
0.02, 0.05
0.001707
0.006268
0.000066
0.001591
0.007357
0.000098
0.000680
0.005271
0.000043
-0.000078
0.006786
0.000075
0.3, 5
0.209712
0.543812
0.572916
0.493983
0.762481
1.184417
0.337317
1.417153
3.323895
0.958836
1.892733
5.972325
0.05, 2
0.206730
0.251102
0.156499
0.320155
0.356562
0.356936
0.501932
0.695099
0.956195
0.737981
0.904887
1.761379
100
3
0.02, 0.05
0.004989
0.012495
0.000293
0.004451
0.016137
0.000483
0.000897
0.007160
0.000081
-0.001198
0.010670
0.000173
0.3, 5
0.867955
1.100889
2.932451
1.059814
1.356333
4.983397
0.770588
1.216026
2.658104
0.877139
1.441000
3.933093
0.05, 2
0.431200
0.466580
0.531628
0.539306
0.582099
1.067997
0.456392
0.558029
0.568953
0.523228
0.652936
0.872355
5
0.02, 0.05
0.001778
0.005664
0.000055
0.001718
0.006716
0.000082
0.000839
0.004859
0.000038
0.000443
0.006135
0.000060
0.3, 5
0.218949
0.535202
0.552218
0.420245
0.700898
1.018933
0.349058
1.399999
3.103568
0.795703
1.808621
5.484757
0.05, 2
0.168868
0.215696
0.126635
0.265858
0.302138
0.246075
0.411721
0.617124
0.793489
0.645761
0.806164
1.394646
Some of the main observations from simulation results are listed in the following.
-
The MLE of the parameters are consistent, i.e., AB and MSE decrease with n.
-
The AB and MSE have larger values for censored data ( ) rather than uncensored data.
6 Applications
Shanker (2016a,b) analyzed a data set consisting of the number of cycles to failure for 25 yarn samples. The data are: 15, 20, 38, 42, 61, 76, 86, 98, 121, 146, 149, 157, 175, 176, 180, 180, 198, 220, 224, 251, 264, 282, 321, 325, 653. The MLE of the parameters of
was calculated from
. For
, we have the smallest value of the K-S statistic. Thus, the estimated model is
. The K-S statistic and corresponding p-value are
and
, respectively. The AIC value, which corresponds to the MLE, is
. Fig. 6, left panel, shows the empirical CDF and the CDF of the fitted model, and graphically confirms that the model describes the data well. Also, Fig. 8, left panel, draws the histogram of data and the estimated PDFs.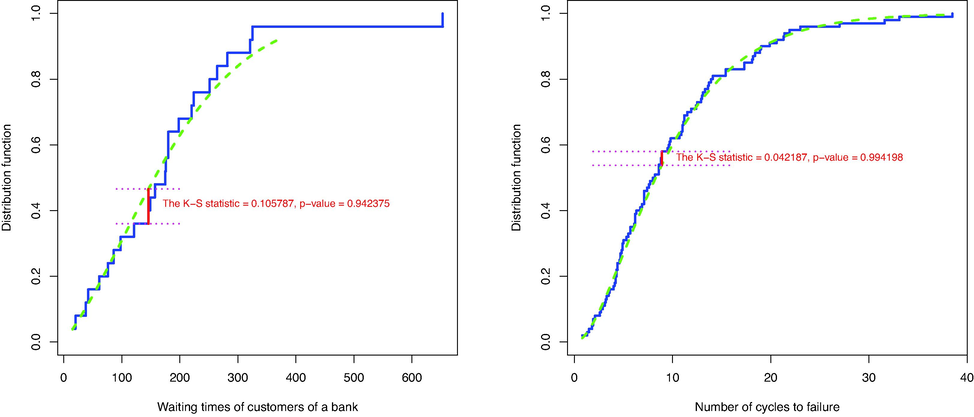
The empirical distribution function along with fitted
.
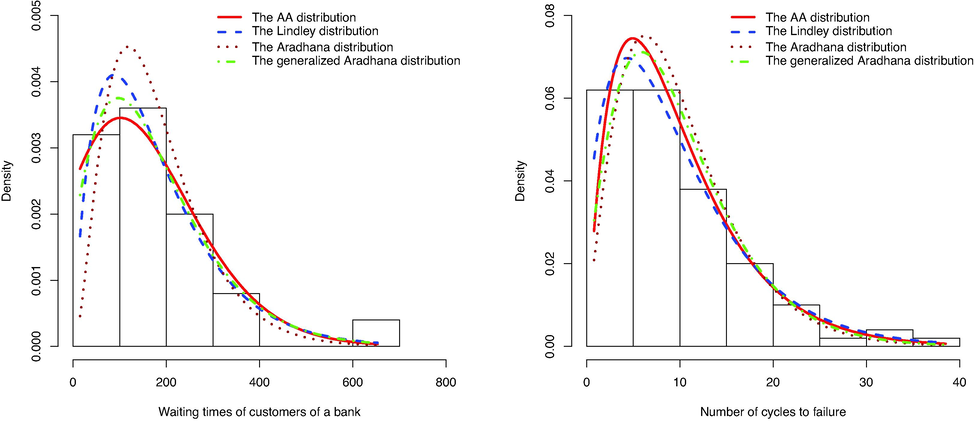
The histogram along with some fitted models for the first data set (left) and the second data set (right).
The second data set consist of 100 waiting times (in minutes) of customers to be served in a bank: 0.8, 0.8, 1.3, 1.5, 1.8, 1.9, 1.9, 2.1, 2.6, 2.7, 2.9, 3.1, 3.2, 3.3, 3.5, 3.6, 4.0, 4.1, 4.2, 4.2, 4.3, 4.3, 4.4, 4.4, 4.6, 4.7, 4.7, 4.8, 4.9, 4.9, 5.0, 5.3, 5.5, 5.7, 5.7, 6.1, 6.2, 6.2, 6.2, 6.3, 6.7, 6.9, 7.1, 7.1, 7.1, 7.1, 7.4, 7.6, 7.7, 8.0, 8.2, 8.6, 8.6, 8.6, 8.8, 8.8, 8.9, 8.9, 9.5, 9.6, 9.7, 9.8, 10.7, 10.9, 11.0, 11.0, 11.1, 11.2, 11.2, 11.5, 11.9, 12.4, 12.5, 12.9, 13.0, 13.1, 13.3, 13.6, 13.7, 13.9, 14.1, 15.4, 15.4, 17.3, 17.3, 18.1, 18.2, 18.4, 18.9, 19.0, 19.9, 20.6, 21.3, 21.4, 21.9, 23.0, 27.0, 31.6, 33.1, 38.5, see Ghitany et al. (2008) and Shanker (2015).
For , the MLEs of the parameters of were calculated. Based on the K-S statistics, the best model among them is . The corresponding AIC value is , and the K-S statistics and p-value are and , respectively, indicating a good fit. Fig. 6, right panel, shows the empirical and fitted CDFs and confirms a good fit.
In a comparative analysis, we fitted the Lindley distribution, the Aradhana distribution, and the generalized Aradhana distribution defined by (1) to these data sets. The MLEs of the parameters of the models were estimated and the results, summarized in Table 2, show that the proposed model
performs better than the others in both examples. Figs. 7 and 8 show the fitted distributions and PDFs respectively.
Data
Model
K-S statistics
K-S p-value
AIC
The first data set
Lindley
0.01115
0.127756
0.762682
307.019
Aradhana
0.016728
0.12346
0.7967
311.0772
Generalized Aradhana
0.013388
0.019097
0.11755
0.8407
308.864
0.022551
0.003368
0.105787
0.942375
306.2316
The second data set
Lindley
0.1866
0.067677
0.7495
640.0784
Aradhana
0.27655
0.080136
0.5419
642.343
Generalized Aradhana
0.2597
0.5556
0.060349
0.8596
641.5076
0.202477
1545.077
0.042187
0.991498
638.6034
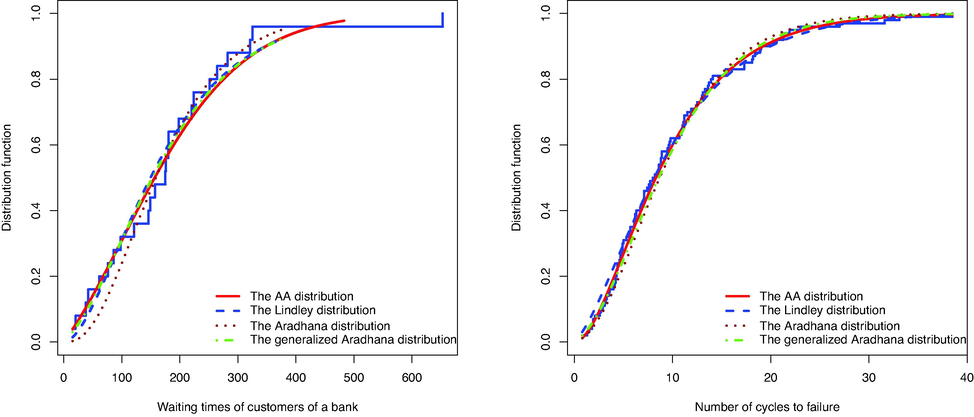
The empirical distribution function along with some fitted models for the first data set (left) and the second data set (right).
7 Conclusion
Because of its applicability and usefulness, the Lindley model and its generalizations have been considered by many authors. Here, a new generalization of the Lindley distribution has been introduced to extend this collection. Some properties of this distribution have been studied. Parameter estimation was discussed using moments and maximum likelihood methods. Simulation studies show that the MLE is efficient and consistent for both complete and right-censored data. The results of fitting the presented model to two real data sets show that it is useful in analyzing data.
Acknowledgments
The authors would like to thank the two anonymous reviewers for their suggestions and very constructive comments that improved the presentation and readability of the paper. This work is supported by Researchers Supporting Project number (RSP-2021/323), King Saud University, Riyadh, Saudi Arabia.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- A new generalized Lindley distribution. J. Stat. Comput. Simul.. 2015;85:3662-3678.
- [Google Scholar]
- A New Flexible Generalized Lindley Model: Properties, Estimation and Applications. Symmetry. 2020;12:1678. URL: https://www.mdpi.com/2073-8994/12/10/1678
- [Google Scholar]
- Al-Babtain A.A., Eid, H.A., A-Hadi N.A., Merovci, F., 2014. The five parameter Lindley distribution. Pakistan J. Stat. 31, 363–384.
- Inferences on stress-strength reliability from Lindley distribution. Commun. Stat. Theory Methods. 2013;42:1443-1463.
- [Google Scholar]
- A new condition for identifiability of finite mixture distributions. Metrika. 2006;63:215-221.
- [CrossRef] [Google Scholar]
- Bader, M.G., Priest, A.M., 1982. Statistical aspects of fiber and bundle strength in hybrid composites. In hayashi, T., Kawata, K. Umekawa, S. (Eds), Progress in Science in engineering Composites, ICCM-IV, Tokyo. 1129–1136.
- The Lindley family of distributions: properties an applications. Hacettepe J. Math. Stat.. 2017;46:1113-1137.
- [Google Scholar]
- The Lindley Weibull Distribution: properties and applications. Acad. Bras. Cienc.. 2018;90(3):2579-2598. PMID:30304208
- [CrossRef] [Google Scholar]
- Fracture mechanics approach to the design of glass aircraft windows: A case study. SPIE Proc.. 1994;2286:419-430.
- [Google Scholar]
- A two-parameter Lindley distribution and its applications to survival data. Math. Comput. Simul.. 2011;81:1190-1201.
- [Google Scholar]
- Survival Distributions: Reliability Applications in the Biometrical Sciences. New York: John Wiley; 1976.
- Mixture models: theory, geometry and applications. In: NSF-CBMS Regional Conference Series in Probability and Statistics. 1995. p. :5.
- [Google Scholar]
- Families of frequency distributions. London, U.K.: Charles Griffin; 1972.
- On Generalized Lindley Distribution and Its Applications to Model Lifetime Data from Biomedical Science and Engineering. Insights Biomed.. 2016;1(2)
- [Google Scholar]
- A two-parameter power Aradhana distribution with properties and application. Indian J. Ind. Appl. Math.. 2018;9:210-220.
- [Google Scholar]
- Statistical analysis of finite mixture distributions. Chichester, U.K.: John Wiley and Sons; 1985.
- A generalized Aradhana distribution with properties and applications. Biometrics Biostat. Int. J.. 2018;7(4):374-385.
- [Google Scholar]




