

Translate this page into:
The integrated model of the Kolmogorov–Smirnov distribution-free statistic approach to process control and maintenance
⁎Corresponding author. adisak.pon@kmutt.ac.th (A. Pongpullponsak)
-
Received: ,
Accepted: ,
This article was originally published by Elsevier and was migrated to Scientific Scholar after the change of Publisher.
Peer review under responsibility of King Saud University.
Abstract
This research is aimed to find the optimal values of four variables (n, h, L, k) that minimize the cost of integrated system approach to process control from considering the basis of the EWMA control chart integrated model (Charongrattanasakul and Pongpullponsak, 2009, 2011) and Kolmogorov–Smirnov (KS) control chart Khrueasom and Pongpullponsak (2014). The proposed mathematical model is used to analyze the cost of the integrated model before the genetic algorithms (GA) approach is carried out in order to calculate the optimal values of four variables (n, h, L, k) that minimize the hourly cost. Subsequently, they are subjects to the nonparametric linear regression test in order to confirm the optimal values of four variables. A comparison between four policies of integrated model KS and other models indicates that the integrated KS model has a better economic behavior when it is distribution-free. Finally, the performance or average run length (ARL) obtained from the KS model is greater than that of the general model.
Keywords
Integrated model
Maintenance Management
Distribution-free
Kolmogorov–Smirnov
Nonparametric linear regression
Genetic algorithms

1 Introduction
Since the first control chart was provided in 1924 by Dr. Shewhart, the concept of the control chart has been considered in many models from past to present, and currently the quality control is widely used in various industry areas. One popular application on control chart used in manufacturing is economic design of control charts. Montgomery (2009) stated that the economic design of control charts refers to the control charts that have been designed with respect to statistical criteria only. This usually involves selecting sample size and control limits such that the average run length (ARL) of the chart to detect a particular shift in the quality characteristic and the ARL of the procedure when the process is in control are equal to specified values. Practically, frequency of sampling is considered from factors including production rate, expected frequency of shifts to an out-of-control state, and possible consequences of such process shifts in determination of sampling interval. In many cases, statistical criteria and practical experience have been used in setting up general guidelines for the design of control charts. One thing that should be noted in designing a control chart is the choice of control chart parameter can cause economic consequences. For this reason, an economic viewpoint such as costs of sampling and testing, costs associated with investigating out-of-control signals and possibly correcting assignable causes, and costs of allowing nonconforming units to reach a consumer should be taken into account in the design of a control chart.
In recent years, considerable research has been devoted to economic models of control charts. Duncan (1956) used optimum methodology to establish design parameters including subgroup size (n), sampling interval (h), and control-limit width (±L standard deviations) for minimizing the loss cost, where the cost items include a sampling and testing cost, an increasing cost from out-of-control process, false alarm cost, and searching and repairing cost. Pongpullponsak et al. (2009) studied a chart in conjunction with an age replacement preventive maintenance policy. From the report, they also introduced an economic model established using the Shewhart method and determined the efficiency of the control chart when the data were in skewed distributions. Saniga (1977) proposed a joint economic design of and R control charts based on two assignable causes in production process. In this model, one assignable cause results in a shift of the process mean whereas the other one results in a shift of the process variance. Yu et al. (2010) studied the possibility in economic statistical design of control charts by considering only one assignable cause. In fact, multiple assignable causes such as machine problem, material deviation, human errors, etc. can occur during the production process so for this research, establishment of an economic-statistical model of control chart will be extended from consideration of single, in the original research, to multiple assignable causes for a real application. Zhou and Zhu (2008) established an economic statistical design of control chart from integrating the concepts between Statistical Process Control (SPC) and Maintenance Management (MM), which are in science and business practice, respectively. The integrated model was then used to find the optimal values of policy variables (n, h, L, k) that minimize hourly cost, subsequently optimal product quality, little downtime, and cost reduction can be achieved by controlling variances in the process. The effects of cost parameters on the solution of the design were investigated using a numerical experiment.
Generally, the process in construction of control chart includes gathering the sampling properties of monitoring statistic, determining the chart’s behavior, and comparing its performance with other existing charts. In most cases, the data are treated as normality but in some occasions, the underlying population distribution or the necessary sampling properties could not be ruled out. Some researchers have proposed reasonable alternative as a solution. For instance, Yang et al. (2011) introduced a nonparametric approach, namely a nonparametric EWMA sing control chart for dealing with such situations. The Kolmogorov–Smirnov (KS) control chart is another good example. The knowledge of sampling distribution is useful for nonparametric statistics inference because the exact sampling distributions are considerably easier to calculate compared with that for distribution-free statistic , or Kolmogorov–Smirnov one-sample statistic (Gibbons, 1971). Pongpullponsak and Jayathavaj (2014) considered distribution-free statistics when the population from which selected samples are not normally distributed or normality cannot be met was used. Additionally, there are several nonparametric tests that have been further applied in case of nominal or ordinal data. Bakir (2012) introduced a modified version of the two – sample Kolmogorov–Smirnov test statistic where the difference of the reference and test empirical distribution function are maximized only over the training sample values. Khrueasom and Pongpullponsak (2014) developed the distribution-free or unknown distribution quality control chart based on the KS.
This research is aimed to find the optimal values of four variables (n, h, L, k) that minimize the cost of integrated system approach to process control and maintenance model on the basis of the distribution-free/KS – control chart.
2 Materials and methods
2.1 Nomenclature
Cycle time (E [T])
expected time searching for a false alarm
the expected time to identify maintenance requirement and to perform a planned maintenance
the expected time to determine occurrence of assignable causes
the expected time to identify maintenance requirement and to perform a reactive maintenance
the expected time to perform a compensatory maintenance
the mean elapse time from the last sample before the assignable cause to the occurrence of the assignable
the average run length during the in-control period
the average run length during the out-of- control period
E
the expected time to sample and chart one item
Cycle cost (E [C])
the cost of quality loss per unit time (the process is in an in-control state)
the cost of quality loss per unit time (the process is in an out-of-control state)
the cost of performing planned maintenance
the cost of performing reactive maintenance
the cost of performing compensatory maintenance
the fixed cost of sampling
the variable cost of sampling
the cost to investigate a false alarm
The indicator variable equals 1 if production continues during planned maintenance (
), reactive maintenance (
), compensatory maintenance (
), validate assignable cause (
) or 0 otherwise
the probability that run length of control chart equals i during in-control period
the probability that run length of control chart equals i during out-of- control period
Optimal variable
n
the sampling size (n∗ for optimal)
h
the interval between sampling (h∗ for optimal)
L
the width of control limit in units of standard deviation (L∗ for optimal)
K
the number of samples taken before planned maintenance (k∗ for optimal)
2.2 Problem statement and assumptions
Fig. 1 shows the framework in development of integrated model. The process starts with an in-control state with a process failure mechanism that is distribution-free or follows an unknown distribution. The best-known test is the KS, the cumulative distribution function (cdf) of the sample, called the empirical distribution function (edf), may be considered, and an estimate of the population and
can be written as follows:
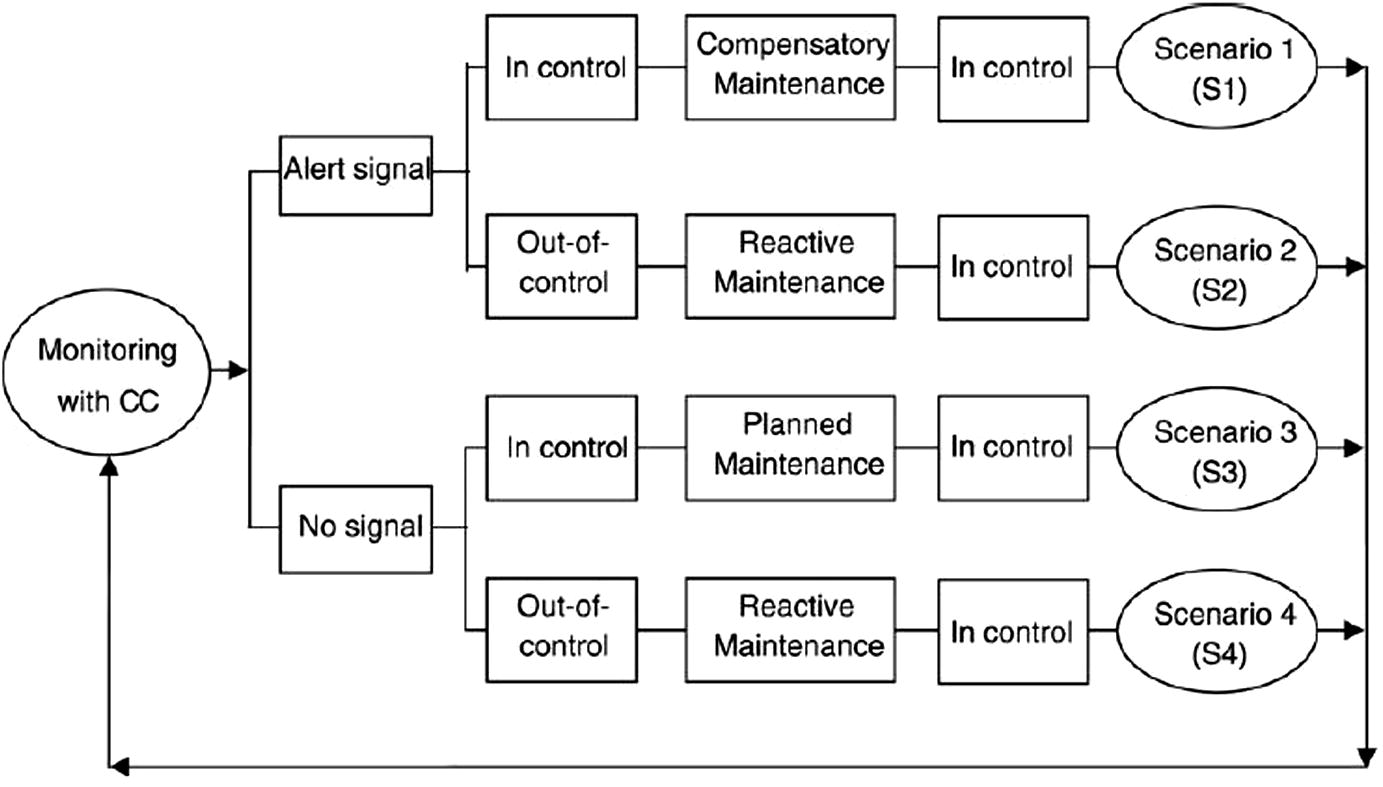
Four monitoring – maintenance scenarios of the integrated mode.
For the random variable Sn(x), which is the edf of a random sample X1, X2, Xn, a distribution FX can be derived from “Nonparametric statistical Inference” by Gibbons (1971),
Define the indicator random variables as below;
The
constitutes a set of n independent random variables from the Bernoulli distribution with parameter
, where
. Therefore, we obtain
The random variables is the sum of n independent Bernoulli random distribution, which follows the binomial distribution with parameter .
From Eqs. (2)–(4), we consider a sequence of t independent Bernoulli trials, where the probability of the event is λ and the probability of the non-event is 1 − λ. If we consider the event to be the elimination of the player, then its absence over n trials can be described as their survival. The probability of this survival throughout t trials will be given by the binomial mass function B (x; t, λ) when x = 0 (Pollock, 2007), which is
Likewise, in the case of the non-occurrence of eliminating event over a continuous finite period of time the model of survival or elimination can be converted through Bernoulli trials into similar model in which the events are distributed randomly in time. To achieve this, a Poisson’s process in continuous time should be depicted as a limiting case of a binomial process. It can be carried out by taking, as the departure point, the special case of the binomial given under Eq. (5) and considering that of each trial representing a single unit of time. Subsequently, the probability of the occurrence of the eliminating event within a single period can be denoted by λ. Also, it is assumed that the probability of the occurrence of two such events within the same interval is vanishingly small or zero.
Then
In the limit, when the number of subdivisions increases indefinitely, we have
At this point, the probability of survival in the period 0, t can be described by
Next, the corresponding density function, defined over the set of times at which elimination might occur, or a probability density function is
2.3 Monitoring scenarios
In Scenario 1, the process begins at “in-control” state. Inspections start after h hours of monitoring to investigate whether or not the process has shifted from an “in-control” to an “out-of-control” state. An alert signal has been added in the control chart before the scheduled time when maintenance should be carried out. But the signal will be false, if the process is still “in-control”. In this case, searching and determining false signal consumes time and incurs cost. Compensatory Maintenance will be performed.
In Scenario 2, there is an alert signal similar to Scenario 1. However, for this case the signal is valid and the process shifts to an “out-of control” state, consequently Reactive Maintenance is active.
In Scenarios 3 and 4, there is no signal in the control chart before the scheduled time. For this reason, at the (k + 1)th sampling interval, appropriate maintenance is assigned. In Scenario 3, since the process is always ‘‘in-control’’, Planned Maintenance is performed. But when the process shifts to an ‘‘out-of-control’’ state, in Scenario 4, Reactive Maintenance will be active. Since the ‘‘out-of-control’’ condition happens before the scheduled time, additional time and expense will be incurred to identify and solve the equipment problem.
The proposed model which consists of four different scenarios has been defined as follows (Fig. 1).
2.4 Economic design of integrated model
2.4.1 Expected cycle time E [T] of each scenario
Scenario 1 (S1), the process begins at an “in-control” state in which inspections start after h hours of monitoring to check whether or not the process has shifted from an “in-control” to “out-of-control” state. An alert signal is added in the control chart when maintenance should be performed before the scheduled time. But the false signal might occur sometimes when the process is still “in-control”, in this case searching and determining false signal, which consumes time and incur cost, will be carried out. Compensatory Maintenance is performed.
The components of the total time of scenario 1 include,
-
The interval time when process is in control, denoted by T1
(13) -
The interval to search for the assignable cause, denoted by T2
(14) -
The interval when the process is in Compensatory Maintenance, denoted by T3
(15) -
The total time of scenario 1 is
(16)
Scenario 2 (S2), it assumes that the process shifts to an “out-of-control” state prior to the planned maintenance, and the process failure mechanism follows a binomial distribution whereas the in-control time follows a truncated binomial distribution as Eqs. (10) and (11).
Then we have
Since D is a binomial random variable with parameters n and p, the β-error defined by Eq. (19) can be obtained from the cumulative binomial (see Appendix). The components of the total time of scenario 2 include,
-
The interval when the process is in control, denoted by T1
(20) -
The interval when the process is out of control before the final sample of the detecting subgroup is taken, denoted by T4
(21) -
The interval to sample, inspect, evaluate and plot the subgroup results, denoted by T5
(22) -
The interval to search for the assignable cause, denoted by T2
(23) -
The interval that the process is in Reactive Maintenance, denoted by T6
(24) -
The total time of scenario 2 is
(25)
Scenario 3 (S3), no signal occurs in the control chart before the scheduled time. Thus at the (k + 1)th sampling interval, appropriate maintenance should be concerned. Since the process is always ‘in-control’’, Planned Maintenance is performed. The components of the total time of scenario 3 include,
-
The interval when the process is in control, denoted by T1
(26) -
The interval when the process is out of control and no signal is assigned in the chart, denoted by T7
(27) -
The interval when the process is in Planned Maintenance, denoted by T8
(28) -
The total time of scenario 3 is
(29)
Scenario 4 (S4), the process begins in control. When the process shifts to an ‘‘out-of-control’’ state before the scheduled time, Reactive Maintenance will be active. This leads to additional time and expense which is used to identify and solve the equipment problem. The components of the total time scenario 4 include,
-
The interval when the process is in control, denoted by T1
(30) -
The interval when the process is out of control and no signal is arranged, denoted by T7
(31) -
The interval when the process is in Reactive Maintenance, denoted by T6
(32) -
The total time of scenario 4 is
(33)
2.4.2 Expected cycle cost E [C] of each scenario
Similarly, the cycle cost consists of three main components including the cost of quality loss incurred while operating the process, the cost of sampling, and the cost of maintenance. The cost of quality loss includes both C1 and C0, these two costs can be estimated using the equations given below,
-
The cost of interval when the process is in control, denoted by C1
(34) -
The cost of sampling, inspection, evaluation and charting, denoted by C2
(35) -
The cost of false alarms, denoted by C3
(36) -
The cost of Compensatory Maintenance, denoted by C4
(37) -
The cost of interval occurred when the process is out of control, denoted by C5
(38) -
The cost of Reactive Maintenance, denoted by C6
(39) -
The cost of Planned Maintenance, denoted by C7
(40)
The total cost for scenario 1
The total cost for scenario 2
The total cost for scenario 3
The total cost for scenario 4
2.4.3 Expected hourly cost E [H]
In this section, determination of the hourly cost E [H] will be carried out. The model can be considered as a renewal-reward process; hence, the expected cost per hour E [H] can be expressed by
3 Results and analysis
In this research, the numerical example and sensitivity analyses are conducted to study the effect of model parameters in the solution of economic design of the KS chart. Using the genetic algorithms (GA) with MATLAB, 7.6.0 (R2009a) software The Math WorksTM, 2009, the solution procedure is carried out to obtain the optimal values of which will be subsequently used to minimize in Eq. (45).
The GA is the stochastic and optimization search technique of natural selection and natural genetics. The GA solves problems used the approach to the process of Darwinian evolution. In recent years, many research have been devoted to the GA solves problems of economic-statistical, engineering, mathematics, production processes, etc. Current, GA models were introduced and investigated by Holland (1975). The solution procedures of GA (e.g., Charongrattanasakul and Pongpullponsak, 2011; Chou et al., 2006, 2008; Lin et al., 2009, 2012; Chen and Yeh, 2009; Franco et al., 2012), in this the research are briefly described below.
Step 1. Initial Population: The procedure starts at randomly generating 100 solutions that reach the constraint condition of individual test parameter. Meanwhile, the constraint condition represented for individual test parameter is set as below,
Step 2. Evaluation: This step, is evaluated through the fitness function. Each solution used the expected cost per hour E [H] in Eq. (45).
Step 3. Selection: The selected function chooses parents (survivors) for the next generation based on their scaled values of the fitness scaling function. The four individual solutions are selected randomly and the best is chosen (For the first generation the chromosome with the lowest cost is selected to replace the highest cost chromosome).
Step 4. Crossover: In this step by step 3, generate new chromosomes for the next generation and a pair of parents (survivors) are selected randomly as shown in this example, parents (survivors) used for crossover operations to produce new chromosomes (or children) for the next generation. This research used crossover rate 0.8 as below, where is the first new chromosome, is the second new chromosome, and R and M are the parent (survivors) chromosomes. If 30 parents (survivors) are randomly selected, then there are 60 children that will be produced. Thus, the population size increases to 90 (i.e., 30 parents (survivors) + 60 children) in this step.
Step 5. Mutation: Mutation function is the small change of genes in chromosomes in the population, suppose that the mutation rate is 0.1, which is also determined by orthogonal array experiment.
In this example, we have 90 solutions and we can randomly select 9 chromosomes to mutate some parameters (or genes) in this step.
Step 6. Stopping criteria: Repeat Step 2 to Step 5 until the stopping criteria is found. In this example, we use ‘‘50 generations or greater than” as our stopping criteria.
The initial values of the necessary parameters are given in Tables 1 and 2, where eight independent parameters which will be tested in the sensitivity analysis and their corresponding level planning are illustrated. Accordingly, the effect of model parameters on the solution of economic design of the KS chart can be investigated by conducting numerical example and sensitivity analysis. For the sensitivity determination, L16 orthogonal-array experimental design shown in Table 3 is used in the test.
Parameter
Value
Parameter
Value
E
0.1
3000
200
0.8
10
0.3
100
1
1000
10
0.05
0.2
0.1
0.6
2000
Model parameter
Level 1
Level 2
10
20
200
400
3000
6000
2000
4000
1000
2000
10
20
0.1
0.2
100
200
Trial
Model parameter
1
10
200
3000
2000
1000
10
0.1
100
2
20
200
3000
2000
1000
20
0.2
200
3
10
400
3000
2000
2000
10
0.2
200
4
20
400
3000
2000
2000
20
0.1
100
5
20
200
6000
2000
1000
20
0.2
100
6
10
200
6000
4000
2000
10
0.2
100
7
20
400
6000
2000
1000
10
0.1
200
8
10
400
6000
2000
1000
10
0.2
200
9
20
200
3000
4000
1000
20
0.1
200
10
10
200
3000
4000
2000
20
0.2
100
11
20
400
3000
2000
1000
20
0.2
100
12
10
400
3000
4000
2000
10
0.1
200
13
10
200
6000
4000
2000
10
0.1
200
14
20
200
6000
4000
1000
20
0.1
100
15
10
400
6000
4000
2000
10
0.1
100
16
20
400
6000
4000
2000
20
0.2
200
Solution
n
h
L
k
E [H]
1
1.001
0.432
2.192
20.094
83.517
2
1.000
0.653
2.000
20.000
126.442
3
1.000
0.101
2.021
20.000
95.067
4
1.145
0.104
2.357
20.000
143.357
5
1.010
1.186
2.412
26.935
171.505
6
1.081
4.994
2.301
39.930
205.515
7
1.000
0.140
2.492
20.000
113.634
8
1.006
0.133
2.001
20.000
102.569
9
1.405
0.776
2.079
20.000
185.375
10
1.000
1.260
2.010
20.000
209.949
11
1.000
0.100
2.000
20.000
71.692
12
1.000
0.100
2.000
20.000
148.564
13
9.238
5.000
2.363
39.999
206.009
14
2.415
4.997
2.189
20.036
204.619
15
2.331
0.289
2.348
22.233
108.610
16
9.596
0.429
2.235
20.576
169.921
After calculation, the best value parameters by L16 orthogonal array are obtained as shown in Table 4. From Table 5, the optimal values of the policy variables that minimize
are found to be
and the corresponding hourly cost is
.
Model parameter
Trial 8
10
400
6000
2000
1000
10
0.2
200
Variable
Integrated model (KS)
n∗
1.006
h∗
0.133
L∗
2.001
k∗
20.000
E [H]
102.569
Table 6 illustrates the output of the nonparametric linear regression applied in order to fit the regression line according to Brown and Mood (1951) where Wilcoxon Matched–Pair Test (Corder and Foreman, 2009) is used in hypothesis testing at 0.05 significance levels by the statistical software SPSS 15.0. It is noticed that the sign of the coefficient parameter of constant is often estimated by assuming that the hourly cost E [H] is positive, which is consistent with the principle of nonparametric statistical hypothesis testing.
Parameter
Estimate
T
P-values
Constant (n)
0.7492
15⁎
0.012
E [H]
0.0027
Constant (h)
−1.0426
33⁎
0.012
E [H]
0.0122
Constant (L)
1.9910
7.5⁎
0.012
E [H]
0.0012
Constant (k)
19.6618
25⁎
0.012
E [H]
0.0034
Using nonparametric linear regression test, the numerical results of the optimal values of the policy variables which minimize
are found to be
and the corresponding hourly cost is
(Table 7). In Table 8, the comparison between four policies of the integrated model (KS) and other models shows that the model proposed in this study has a better economic behavior when it is distribution-free.
Variable
Integrated model (KS)
n∗
1.026
h∗
0.209
L∗
2.114
k∗
20.011
E [H]
102.569
Variable
Integrated model (X-bar)
Integrated model (EWMA for four variables)
Integrated model (EWMA for six variables)
Integrated model (KS)
n⁎
4.000
4.000
6.082
1.026
h⁎
1.230
1.150
3.008
0.209
L⁎
2.910
1.100
2.494
2.114
k⁎
22.000
22.000
20.660
20.011
E [H]
158.32
153.020
194.640
102.569
Finally, from Table 9, it can be seen that the performance for ARL of KS control chart, equals to 430.96, is greater than that of the control chart with the general model which is 370.
ARL for the general
ARL for the KS
370
430.96
4 Conclusion
This research proposes the method used in searching the appropriate products for the Kolmogorov–Smirnov KS control chart that is distribution-free. This control chart is suitable for detection of small changes. In some occasions, small changes in the process can lead to incredible damage. For this reason, those factories who produce non-restricted goods using appropriate control charts would reduce or eliminate unnecessary cost. Conclusively, these four control charts shown in Table 8 are suitable for using in various types of factories and products; however, selection of appropriate control chart is recommended in order to reduce unnecessary cost.
The numerical results, when sample size is used, are summarized in Table 8. According to the optimal values of the policy variables that minimize E [H], this provides evidence that when it is distribution-free the integrated KS model will have a better economic behavior than those previously reported models (Charongrattanasakul and Pongpullponsak, 2009, 2011). Besides, the results show that the performance for ARL of KS (Table 9), equals to 430.96, is greater than that of the ARL obtained from the general model which is equal to 370. However, the proposed model may have some defective in which investigating any weak point and improving for better performance would be an interesting issue for further study.
5 Future work
For future work, it is of interest to develop integrated economic model and control chart for nonparametric multivariate which is distribution-free or follows an unknown distribution.
Acknowledgements
The authors would like to thank the referees for their constructive comments and suggestions. This research was financially supported by Department of Mathematics, King Mongkut’s University of Technology Thonburi.
References
- A nonparametric shewhart-type quality control chart for monitoring broad changes in a process distribution. Int. J. Qual. Stat. Reliab. 2012:10.
- [Google Scholar]
- On median tests for linear hypotheses. Proc. Berkeley Sympos. Math. Stat. Probab. 1951:159-166.
- [Google Scholar]
- Minimizing the cost of an integrated model by EWMA control chart. Kasetsart J. (Nat. Sci.). 2009;43:385-391.
- [Google Scholar]
- Minimizing the cost of integrated systems approach to process control and maintenance model by EWMA control chart using genetic algorithm. Expert Syst. Appl.. 2011;38:5178-5186.
- [Google Scholar]
- Economic statistical design of non-uniform sampling scheme X bar control charts under non-normality and Gamma shock using genetic algorithm. Expert Syst. Appl.. 2009;36:9488-9497.
- [Google Scholar]
- Economic design of variable sampling intervals T2 control charts using genetic algorithms. Expert Syst. Appl.. 2006;30:233-242.
- [Google Scholar]
- Economic design of variable sampling intervals EWMA charts with sampling at fixed times using genetic algorithms. Expert Syst. Appl.. 2008;34:419-426.
- [Google Scholar]
- Nonparametric Statistics for Non-Statisticians. John Wiley & Sons; 2009.
- The economic design of charts used to maintain current control process. J. Am. Stat. Assoc.. 1956;51(274):228-242.
- [Google Scholar]
- Economic-statistical design of the chart used to control a wandering process mean using genetic algorithm. Expert Syst. Appl.. 2012;39:12961-12967.
- [Google Scholar]
- Nonparametric Statistical Inference. McGraw-Hill Inc; 1971.
- Adaptation in Natural and Artificial Systems. Ann Arbor, Univ. Michigan Press; 1975.
- Quality control chart based on the Kolmogorov-Smirnov structure. In: Proceedings of International Conference on Applied Statistics (ICAS 2014). 2014. p. :79-84. (Khon Kaen, Thailand)
- [Google Scholar]
- SPSS 15.0 for Windows Serial; License Number 5045778, Single License, SPSS Thailand.
- Economic design of variable sampling intervals charts with A&L switching rule using genetic algorithms. Expert Syst. Appl.. 2009;36:3048-3055.
- [Google Scholar]
- Economic design of autoregressive moving average control chart using genetic algorithms. Expert Syst. Appl.. 2012;39:1793-1798.
- [Google Scholar]
- Introduction to Statistical Quality Control (sixth ed.). New York: John Wiley & Sons; 2009.
- Pollock, S.G., September 2007. Topics in Econometrics. Hazard, Survival and Duration, 1–2. Retrieved January, 2006, from Department of Economics, The University of Leicester. World Wide Web: <http://www.le.ac.uk/users/dsgp1/COURSES/TOPICS/hazard.pdf>, accessed January 2015.
- The new Hodges–Lehmann estimator control charting technique for the known process distributions. In: Proceedings of International Conference on Applied Statistics (ICAS 2014). 2014. p. :47-58. (Khon Kaen, Thailand)
- [Google Scholar]
- The economic model of control chart using shewhart method for skewed distributions. J. Thai Stat. Assoc.. 2009;7(1):81-99.
- [Google Scholar]
- Joint economically optimal design of and R control charts. Manage. Sci.. 1977;24(4):420-431.
- [Google Scholar]
- The Math WorksTM, 2009. MATLAB 7.6.0 (R2009a). License Number 350306, February 12, 2009.
- A new nonparametric EWMA sing control chart. Expert Syst. Appl.. 2011;38(5):6239-6243.
- [Google Scholar]
- An economic-statistical design of control charts with multiple assignable causes. J. Qual.. 2010;17(4):327-338.
- [Google Scholar]
- Economic design of integrated model of control chart and maintenance. Math. Comput. Model.. 2008;47:1389-1395.
- [Google Scholar]
Appendix A
Computation of ARL of the KS control chart
In Eqs. (1) and (2), application of the operating-characteristic function and ARL calculations from Montgomery (2009) is considered.
Since D is a binomial random variable with parameters n and p, the β-error defined in Eq. (A.1) can be obtained from the cumulative binomial distribution, where p is assumed to be
, the edf in Eq. (2), in this case
Then the ARL can be computed by Eq. (2).
Example in Eq. (A1) in calculation it is initially needed to generate the OC curve for a control chart for fraction nonconforming with parameters n = 20, CL = 0.06, LCL = 0, and UCL = 0.13 by considering the concept from the Kolmogorov–Smirnov quality control chart. Using these parameters [3] in Eq. (A1), we obtain
Since D must be an integer, it is find that




